Техника консистентного хеширования consistent hashing довольно популярна при создании распределенных систем, тем не менее я не смог найти описания алгоритма на русском языке. Попробую изложить, возможно кому-то пригодится.
Проблема
Предположим вы разрабатываете приложение и решили кешировать данные для улучшения производительности. Так же вы решили использовать горизонтальное масштабирование и разнести данные на N серверов.
Итого, есть N серверов и необходимо реализовать две функции:
1 2 | |
Имея ключ k, как узнать на каком сервере лежит соответствующий ему элемент?
Решение
Первое что приходит в голову - использовать обычную хеш-таблицу. Берем ключ k, применяем к нему хеш-функцию и считаем остаток от деления на количество серверов N - hash(k) mod N. Да, это будет работать, но что произойдет когда мы захотим добавить ещё один сервер ? Нам необходимо будет перехешировать все данные, большую часть которых нужно будет загрузить на новые сервера. Это дорогая операция. Также не понятно что делать в случае падения существующего сервера.
Здесь появляется консистентное кеширование. Идея простая, возьмем окружность и будем рассматривать ее как интервал на котором определена хеш-функция функция. Применив хеш-функцию к набору ключей (синие точки) и серверов (зеленые точки) сможем разместить их на окружности.
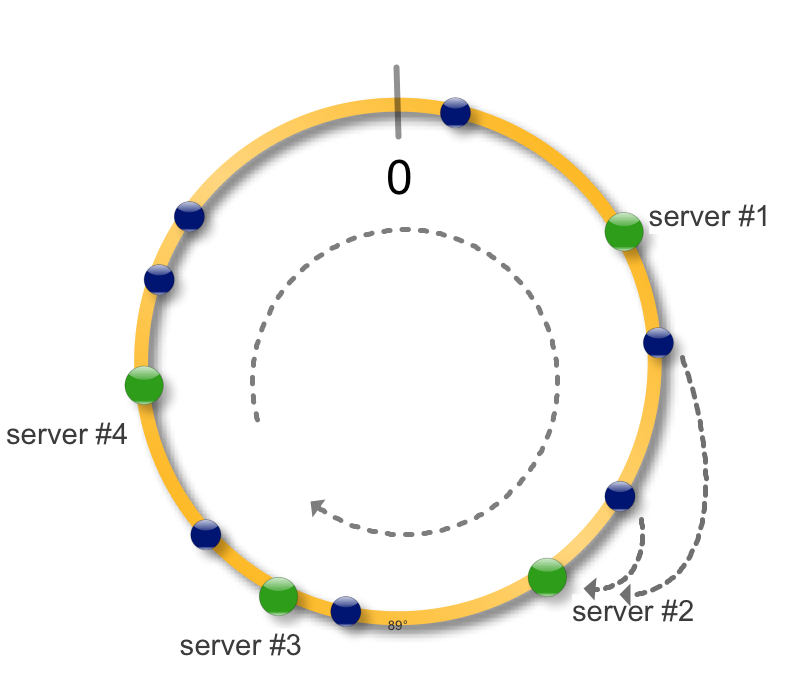
Для того чтобы определить на каком сервере размещен ключ, найдем ключ на окружности и будем двигаться по часовой стрелке до ближайшего сервера.
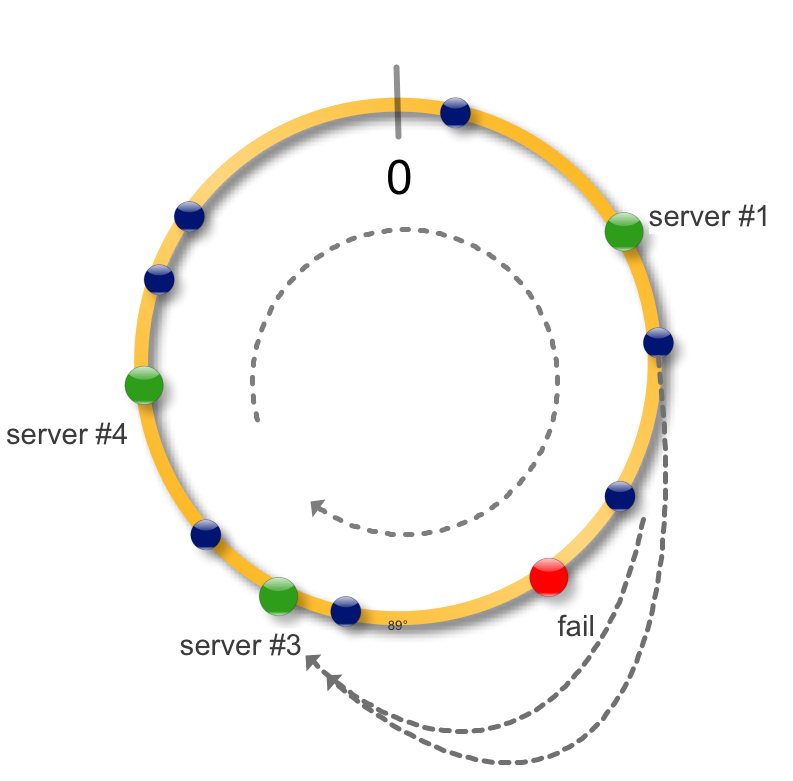
Теперь в случае падения (недоступности) сервера, загрузить на новые сервер необходимо только недоступные данные. Все остальные хеши не меняют свое местоположение, то есть консистенты.
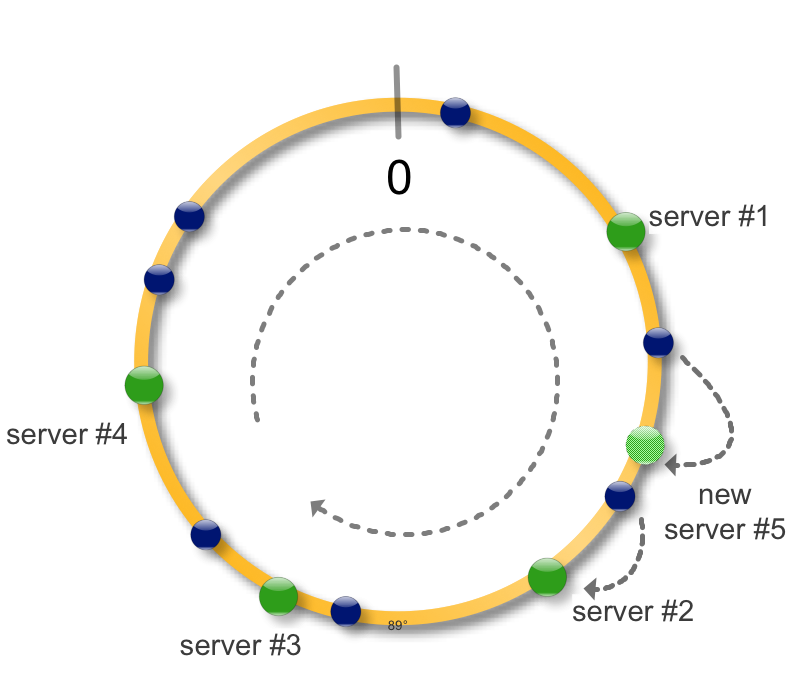
При добавлении нового сервера соседний разделяет с ним часть своих данных.
В целом ето все. На практике также применяют следующий трюк. Сервер можно пометить на окружности не одной точкой, а несколькими.
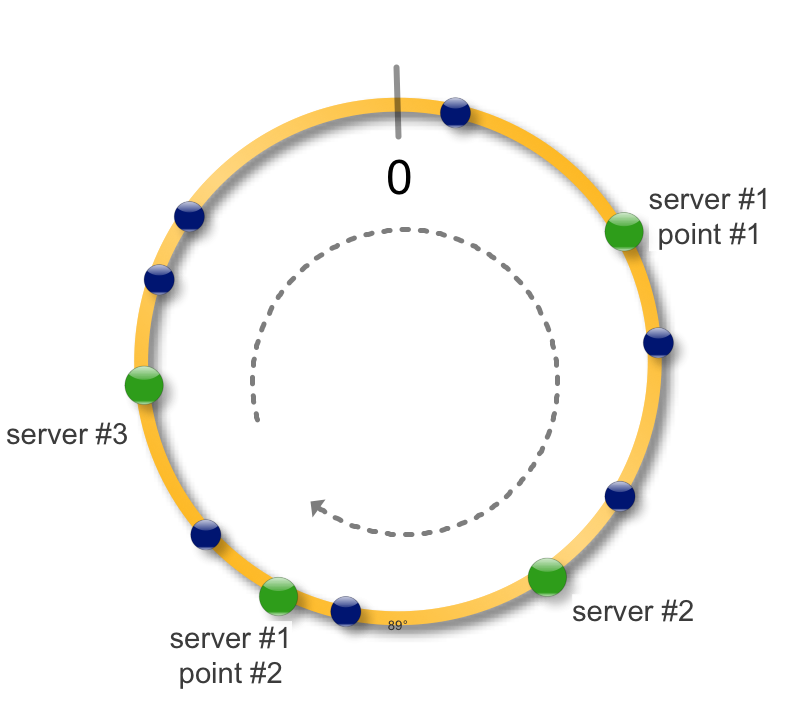
Что ето дает ? - более равномерное распределение данных по серверам - при падении сервера данные распределяются не на один соседний, а на несколько, распределяя тем самым нагрузку - при добавлении нового сервера, точки можно делать ‘активными’ постепенно одна за другой, предотвращая шквальную нагрузку на сервер - если конфигурация серверов отличается, например размером диска, количество данных можно контролировать числом его точек. Больше точек - большая длина окружности принадлежит етому серверу и соответственно больше данных.
Реализация
Храним хеши серверов в виде какого-либо дерева, например Red-Black. Операция поиска сервера по ключу будет занимать O(log n).