A couple of weeks ago we launched InsightEdge, introducing you to our high performance Spark distribution with enterprise-grade OLTP capabilities. In this blog post, we will create a demo application for a taxi price surge use case that runs real-time analytics on a streaming geospatial data.
We take a fundamental supply and demand economic model of price determination in a market. We will then compute price in real-time based on the current supply and demand.
To make our demo even more fun, we will create a taxi price surge use case. We will consider the transportation business domain, and taxi companies like Uber or Lyft in particular.
In taxi services, the order requests and available drivers represent the supply and demand data correspondingly. It is interesting that this data is bound to geographical location, which introduces additional complexity. Comparing to business areas like retail, where the product demand is linked to either offline store or a well known list of warehouses, the order requests are geographically distributed.
With services like Uber, the fare rates automatically increase when the taxi demand is higher than drivers around you. The Uber prices are surging to ensure reliability and availability for those who agree to pay a bit more.
Taxi Price Surge Use Case – 3 Key Architectural Questions
- How do we handle the events like an ‘Order Request’ event or a ‘Pickup’ event?
- How do we compute the price accounting the nearby requests? We will need to find an efficient way to execute geospatial queries.
- How can we scale technology to run business in many cities, states or countries?
Architecture
The following diagram illustrates the application architecture:
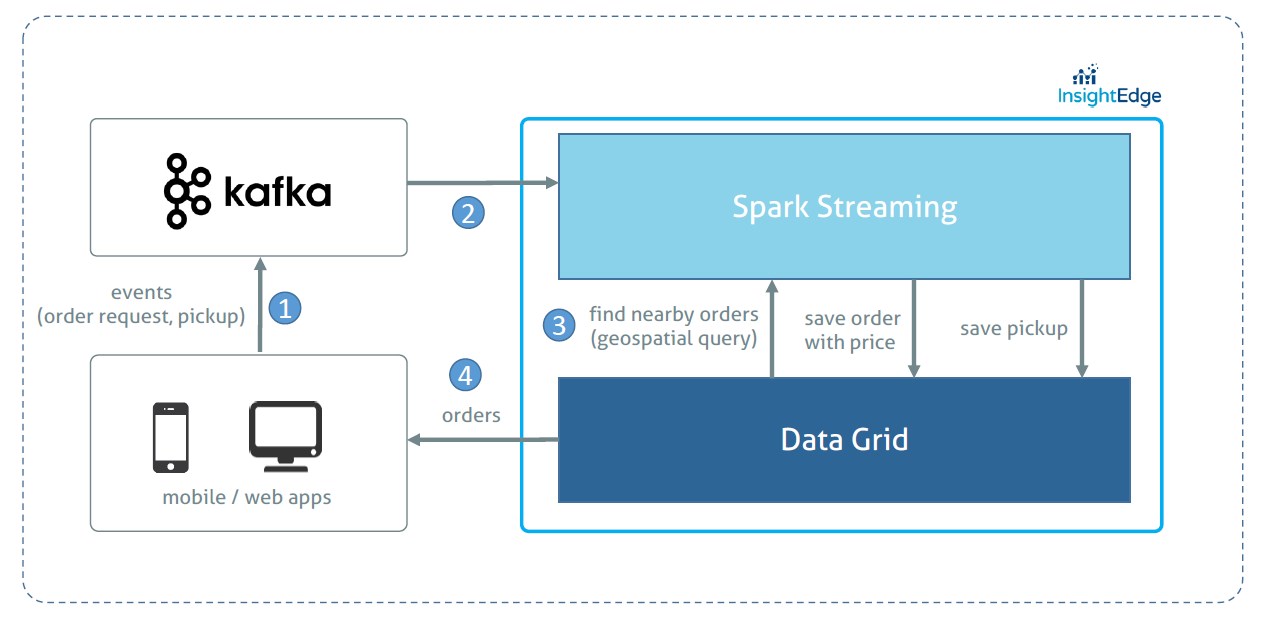
How Does this Architecture Addresses Our 3 Key Questions?
With InsightEdge Geospatial API we are able to efficiently find nearby orders and, therefore, minimize the time required to compute the price. The efficiency comes from the ability to index order request location in the datagrid.
Kafka allows to handle a high throughput of incoming raw events. Even if the computation layer starts processing slower(say during the peak hour), all the events will be reliably buffered in Kafka. The seamless and proven integration with Spark makes it a good choice for streaming applications.
InsightEdge Data Grid also plays a role of a serving layer handling any operational/transactional queries from web/mobile apps.
All the components(Kafka and InsightEdge) can scale out almost linearly;
To scale to many cities, we can leverage data locality principle through a full pipeline (Kafka, Spark, Data Grid) partitioning by the city or even with a more granular geographical units of scale. In this case the geospatial search query will be limited to a single Data Grid partition. We leave this enhancement out of the scope of the demo.
Building a Demo Application for a Taxi Price Surge Use Case
To simulate the taxi orders we took a csv dataset with Uber pickups in New York City. The demo application consists of following components:
- Feeder application, reads the csv file and sends order and pickup events to Kafka
- InsightEdge processing, a Spark Streaming application that reads from Kafka, computes price and saves to datagrid
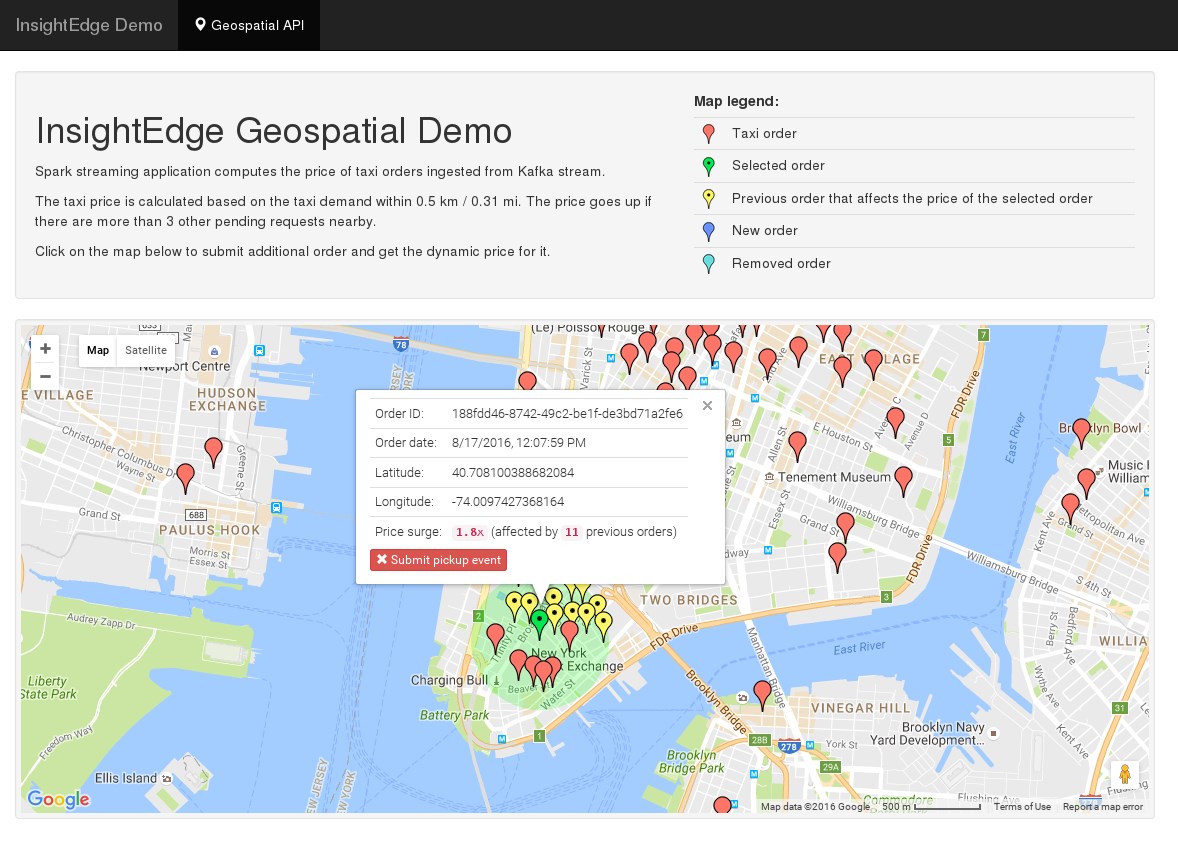
- Web app, reads orders from datagrid and visualizes them on a map
Coding Processing Logic with InsightEdge API
Let’s see how InsightEdge API can be used to calculate the price:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
- Step 1: Initialize a stream of Kafka
orderstopic - Step 2: Parse Kafka message that is in Json format (in real app you may want to use formats like Avro)
- Step 3: For every order we find other non-processed orders within 0.3 km using InsightEdge’s
zipWithGridSql()function - Step 4: Given near orders, we calculate the price with a simple linear function
- Step 5: Finally we save the order details including price and near order ids into the data grid with
saveToGrid()function
The full source of the application is available on github
Taxi Price Surge Use Case Summary
In this blog post we created a demo application that processes the data stream using InsightEdge geospatial features.
An alternative approach for implementing dynamic price surging can use machine learning clustering algorithms to split order requests into clusters and calculate if the demand within a cluster is higher than the supply. This streaming application saves the cluster details in the datagrid. Then, to determine the price we execute a geospatial datagrid query to find which cluster the given location belongs to.