Apache Kafka is a distributed publish-subscribe messaging system. It is designed to support persistent messaging with a O(1) disk structures that provides constant time performance even with many TB of stored messages. Apache Kafka provides High-throughput even with very modest hardware, Kafka can support hundreds of thousands of messages per second. Apache Kafka supports partitioning the messages over Kafka servers and distributing consumption over a cluster of consumer machines while maintaining per-partition ordering semantics. Many times Apache Kafka is used to perform parallel data load into Hadoop.
This pattern integrates GigaSpaces with Apache Kafka. GigaSpaces’ write-behind IMDG operations to Kafka making it available for the subscribers. Such could be Hadoop or other data warehousing systems using the data for reporting and processing. Sources are available on github
XAP Kafka Integration Architecture
The XAP Kafka integration is done via the SpaceSynchronizationEndpoint interface deployed as a Mirror service PU. It consumes a batch of IMDG operations, converts them to custom Kafka messages and sends these to the Kafka server using the Kafka Producer API.
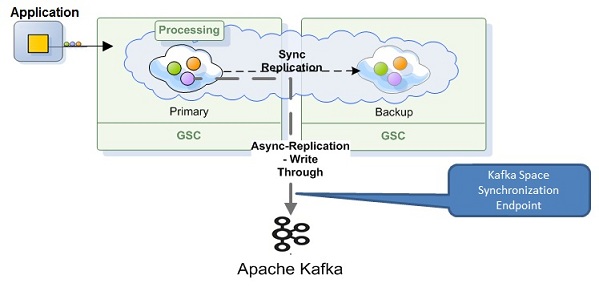
GigaSpace-Kafka protocol is simple and represents the data and its IMDG operation. The message consists of the IMDG operation type (Write, Update , remove, etc.) and the actual data object. The Data object itself could be represented either as a single object or as a Space Document with key/values pairs (SpaceDocument).
Since a Kafka message is sent over the wire, it should be serialized to bytes in some way.
The default encoder utilizes Java serialization mechanism which implies Space classes (domain model) to be Serializable.
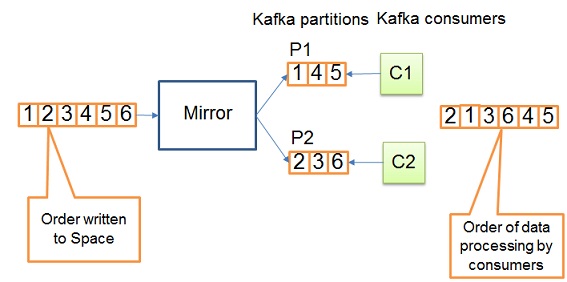
By default Kafka messages are uniformly distributed across Kafka partitions. Please note, even though IMDG operations appear ordered in SpaceSynchronizationEndpoint, it doesn’t imply correct ordering of data processing in Kafka consumers. See below diagram:
Getting started
Download the Kafka Example
You can download the example code from github.
The example located under <project_root>/example. It demonstrates how to configure Kafka persistence and implements a simple Kafka consumer pulling data from Kafka and store in HsqlDB.
Running the Example
In order to run an example, please follow the instruction below:
Step 1: Install Kafka
Step 2: Start Zookeeper and Kafka server
1 2 | |
Step 3: Build project
1 2 | |
Step 4: Deploy example to GigaSpaces
1 2 | |
Step 5: Check GigaSpaces log files, there should be messages from the Feeder and Consumer.
Configuration
Library Dependency
The following maven dependency needs to be included in your project in order to use Kafka persistence. This artifact is built from <project_rood>/kafka-persistence source directory.
1 2 3 4 5 | |
Mirror service
Here is an example of the Kafka Space Synchronization Endpoint configuration:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Please consult Kafka documentation for the full list of available producer properties. You can override the default properties if there is a need to customize GigaSpace-Kafka protocol. See Customization section below for details.
Space class
In order to associate a Kafka topic with the domain model class, the class needs to be annotated with the @KafkaTopic annotation and declared as Serializable. Here is an example
1 2 3 4 5 | |
Space Documents
To configure a Kafka topic for a SpaceDocuments or Extended SpaceDocument, the property KafkaPersistenceConstants.SPACE_DOCUMENT_KAFKA_TOPIC_PROPERTY_NAME should be added to document. Here is an example
1 2 3 4 5 6 | |
It’s also possible to configure the name of the property which defines the Kafka topic for SpaceDocuments. Set spaceDocumentKafkaTopicName to the desired value as shown below.
1 2 3 4 | |
Kafka consumers
The Kafka persistence library provides a wrapper around the native Kafka Consumer API for the GigaSpace-Kafka protocol serialization. Please see com.epam.openspaces.persistency.kafka.consumer.KafkaConsumer, example of how to use it under <project_root>/example module.
Customization
- Kafka persistence was designed to be extensible and customizable.
- If you need to create a custom protocol between GigaSpace and Kafka, provide an implementation of
AbstractKafkaMessage,AbstractKafkaMessageKey,AbstractKafkaMessageFactory. - If you would like to customize how data grid operations are sent to Kafka or how the Kafka topic is chosen for a given entity, provide an implementation of ‘AbstractKafkaSpaceSynchronizationEndpoint’.
- If you want to create a custom serializer, look at
KafkaMessageDecoderandKafkaMessageKeyDecoder. - Kafka Producer client (which is used under the hood) can be configured with a number of settings, see Kafka documentation.