Real-time processing is becoming very popular, and Storm is a popular open source framework and runtime used by Twitter for processing real-time data streams. Storm addresses the complexity of running real time streams through a compute cluster by providing an elegant set of abstractions that make it easier to reason about your problem domain by letting you focus on data flows rather than on implementation details.
Storm has many use cases: realtime analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. Storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.
This pattern integrates XAP with Storm. XAP is used as stream data source and fast reliable persistent storage, whereas Storm is in charge of data processing. We support both pure Storm and Trident framework.
As part of this integration we provide classic Word Counter and Twitter Reach implementations on top of XAP and Trident.
Also, we demonstrate how to build highly available, scalable equivalent of Realtime Google Analytics application with XAP and Storm. Application can be deployed to cloud with one click using Cloudify.
Sources are available on github
- Storm in a Nutshell
- Spouts
- Trident State
- Storm bolts
- Illustrative example: Real-time Google Analytics
- High-level architecture diagram
- Google Analytics Topology. High level overview.
- Top urls topology branch
- Active users topology branch
- Page view time series topology branch
- Geo topology branch
- Building the Application
- Deploying in development environment
- Deploying in development environment with embedded Storm
- Deploying to cloud
Storm in a Nutshell
Storm is a real time, open source data streaming framework that functions entirely in memory. It constructs a processing graph that feeds data from an input source through processing nodes. The processing graph is called a “topology”. The input data sources are called “spouts”, and the processing nodes are called “bolts”. The data model consists of tuples. Tuples flow from Spouts to the bolts, which execute user code. Besides simply being locations where data is transformed or accumulated, bolts can also join streams and branch streams.
Storm is designed to be run on several machines to provide parallelism. Storm topologies are deployed in a manner somewhat similar to a webapp or a XAP processing unit; a jar file is presented to a deployer which distributes it around the cluster where it is loaded and executed. A topology runs until it is killed.
Beside Storm, there is a Trident – a high-level abstraction for doing realtime computing on top of Storm. Trident adds primitives like groupBy, filter, merge, aggregation to simplify common computation routines. Trident has consistent, exactly-once semantics, so it is easy to reason about Trident topologies.
Capability to guarantee exactly-once semantics comes with additional cost. To guarantee that, incremental processing should be done on top of persistence data source. Trident has to ensure that all updates are idempotent. Usually that leads to lower throughput and higher latency than similar topology with pure Storm.
Spouts
Basically, Spouts provide the source of tuples for Storm processing. For spouts to be maximally performant and reliable, they need to provide tuples in batches, and be able to replay failed batches when necessary. Of course, in order to have batches, you need storage, and to be able to replay batches, you need reliable storage. XAP is about the highest performing, reliable source of data out there, so a spout that serves tuples from XAP is a natural combination.
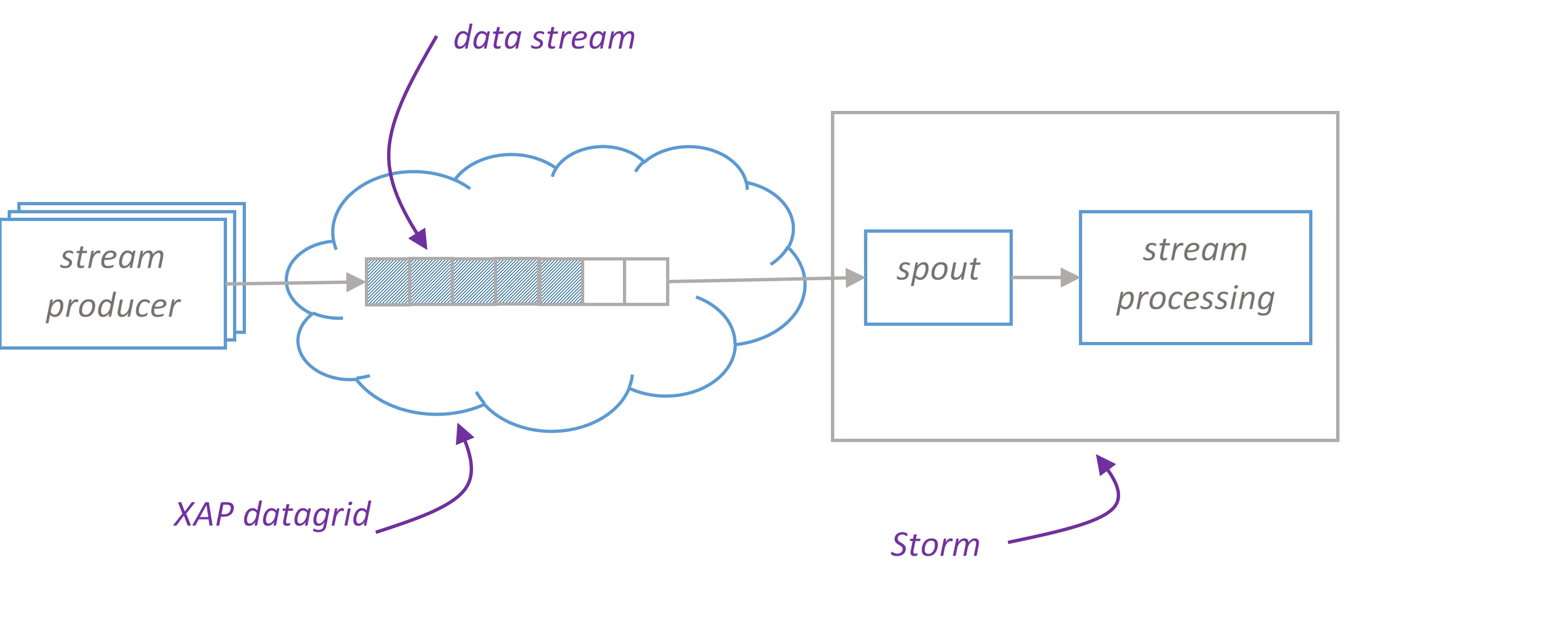
Depending on domain model and level of guarantees you want to provide, you choose either pure Storm or Trident. We provide Spout implementations for both – XAPSimpleSpout and XAPTranscationalTridentSpout respectively.
Storm Spout
XAPSimpleSpout is a spout implementation for pure Storm that reads data in batches from XAP. On XAP side we introduce conception of stream. Please find SimpleStream – a stream implementation that supports writing data in single and batch modes and reading in batch mode. SimpleStream leverages XAP’s FIFO(First In, First Out) capabilities.
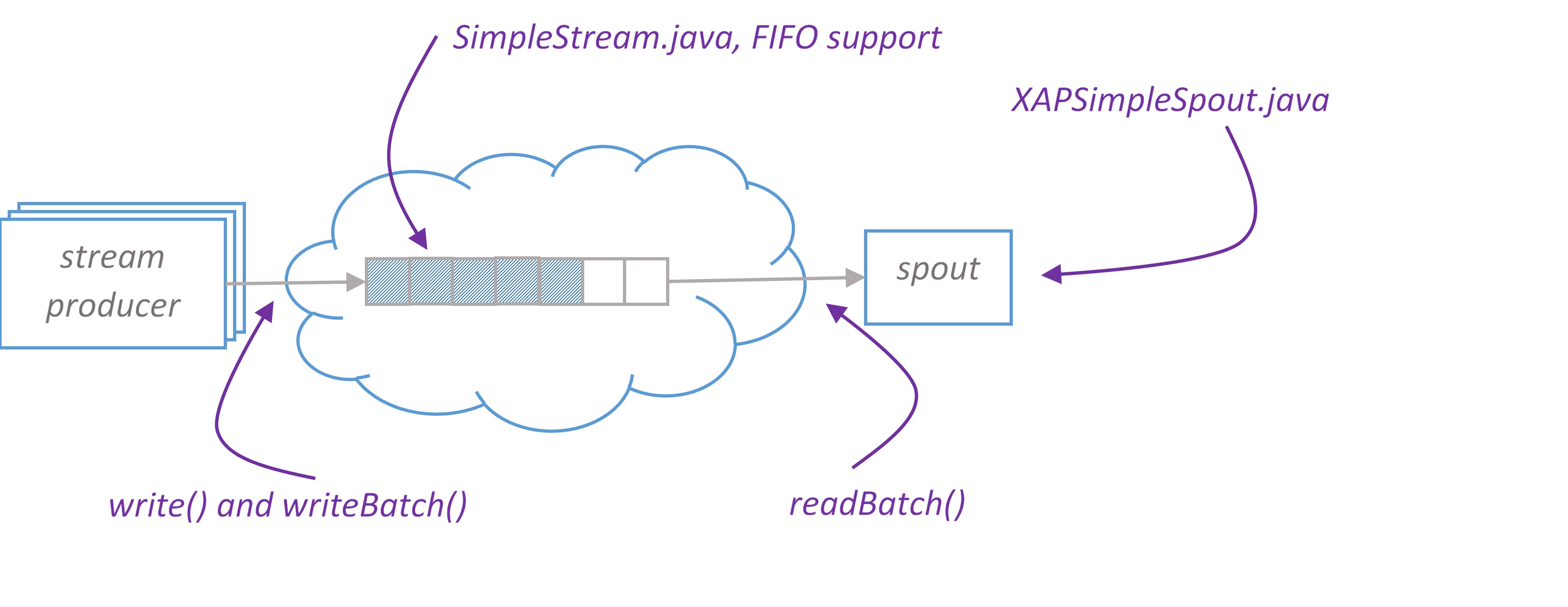
SimpleStream works with arbitrary space class that has FifoSupport.OPERATION annotation and implements Serializable.
Here is an example how one may write data to SimpleStream and process it in Storm topology. Let’s consider we would like to build an application to analyze the stream of page views (user clicks) on website. At first, we create a data model that represents a page view
1 2 3 4 5 6 7 | |
Now we would like to create a reference to stream instance and write some data.
1 2 | |
The second argument of SimpleStream is a template used to match objects during reading.
If you want to have several streams with the same type, template objects should differentiate your streams.
Now let’s create a spout for PageView stream.
1 2 3 4 5 | |
To create a spout, we have to specify how we want our space class be converted to Storm tuple. That is exactly what TupleConverter knows about.
1 2 3 4 5 6 7 8 9 10 11 | |
At this point we have everything ready to build Storm topology with PageViewSpout.
1 2 3 4 5 | |
ConfigConstants.XAP_SPACE_URL_KEY is a space URL
ConfigConstants. XAP_STREAM_BATCH_SIZE is a maximum number of items that spout reads from XAP with one hit.
Trident Spout
XAPTranscationalTridentSpout is a scalable, fault-tolerant, transactional spout for Trident, supports pipelining. Let’s discuss all its properties in details.
For spout to be maximally performant, we want an ability to scale the number of instances to control the parallelism of reader threads.
There are several spout APIs available that we could potentially use for our XAPTranscationalTridentSpout implementation:
IPartitionedTridentSpout: A transactional spout that reads from a partitioned data source. The problem with this API is that it doesn’t acknowledge when batch is successfully processed which is critical for in memory solutions since we want to remove items from the grid as soon as they have been processed. Another option would be to use XAP’s lease capability to remove items by time out. This might be unsafe, if we keep items too long, we might consume all available memory.ITridentSpout: The most general API. Setting parallelism hint for this spout to N will create N spout instances, single coordinator and N emitters. When coordinator issues new transaction id, it passes this id to all emitters. Emitter reads its portion of transaction by given transaction id. Merged data from all emitters forms transaction.
For our implementation we choose ITridentSpout API.
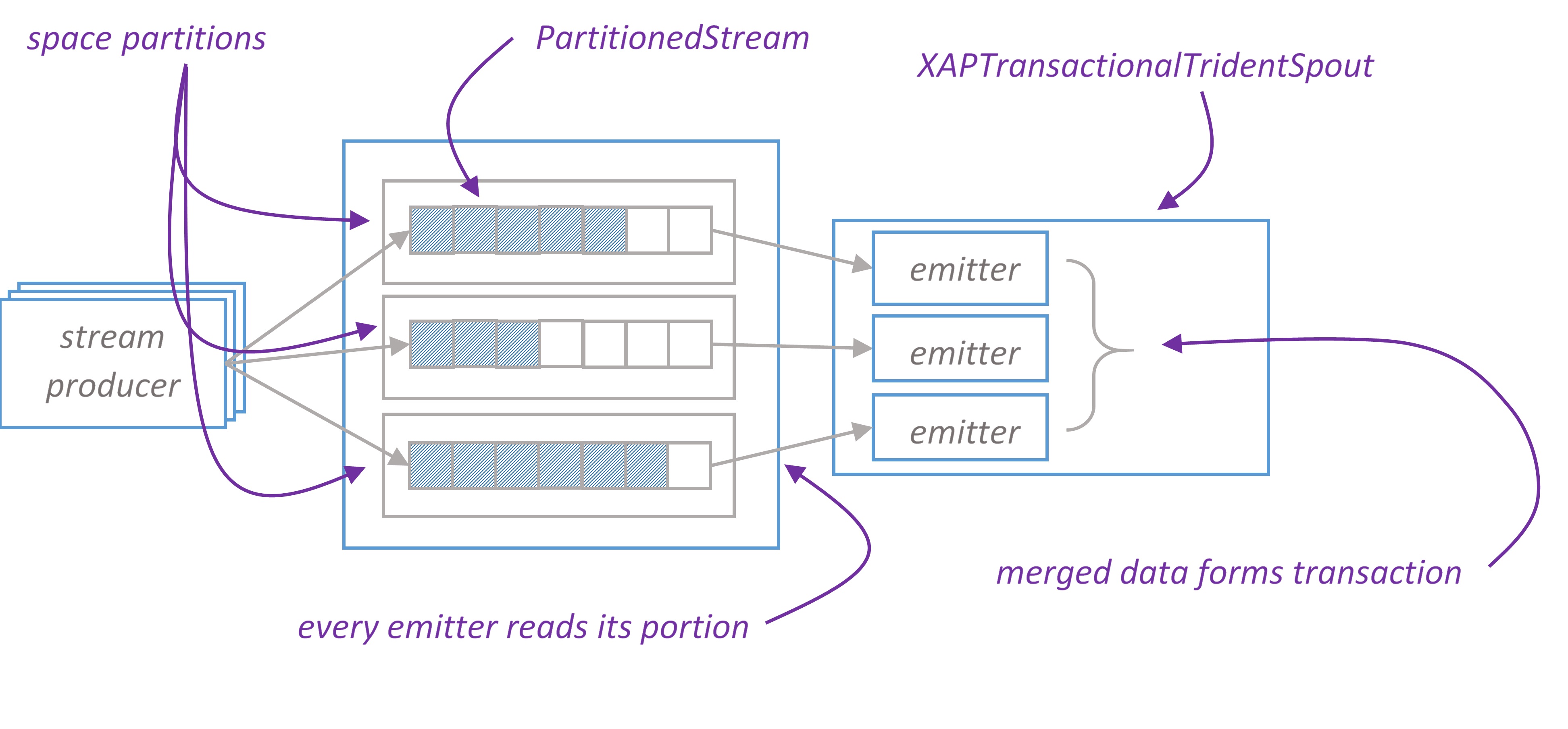
There is one to one mapping between XAP partitions and emitters.
Storm framework guarantees that topology is high available, if some component fails, it restarts it. That means our spout implementation should be stateless or able to recover its state after failure.
When emitter is created, it calls remote service ConsumerRegistryService to register itself. ConsumerRegistryService knows the number of XAP partitions and keeps track of the last allocated partition. This information is reliably stored in the space, see ConsumerRegistry.java.
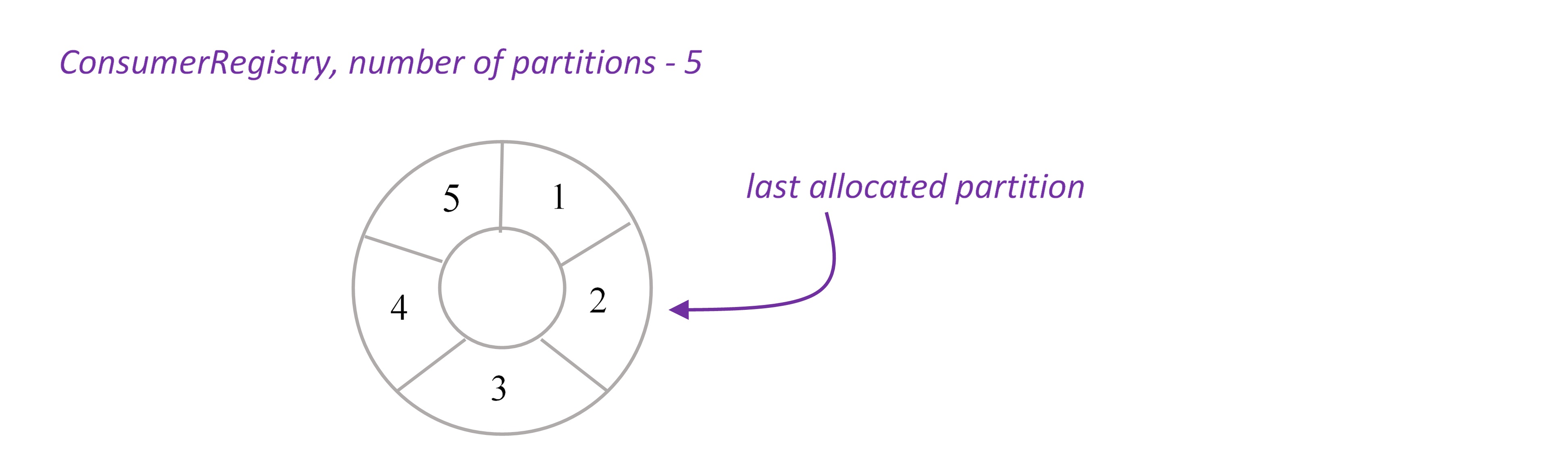
Remember that parallelism hint for XAPTranscationalTridentSpout should equal to the number of XAP partitions.
The property of being transactional is defined in Trident as following: - batches for a given txid are always the same. Replays of batches for a txid will exact same set of tuples as the first time that batch was emitted for that txid. - there’s no overlap between batches of tuples (tuples are in one batch or another, never multiple). - every tuple is in a batch (no tuples are skipped)
XAPTranscationalTridentSpout works with PartitionedStream that wraps stream elements into Item class and keeps items ordered by ‘offset’ property. There is one PartitionStream instance per XAP partition.
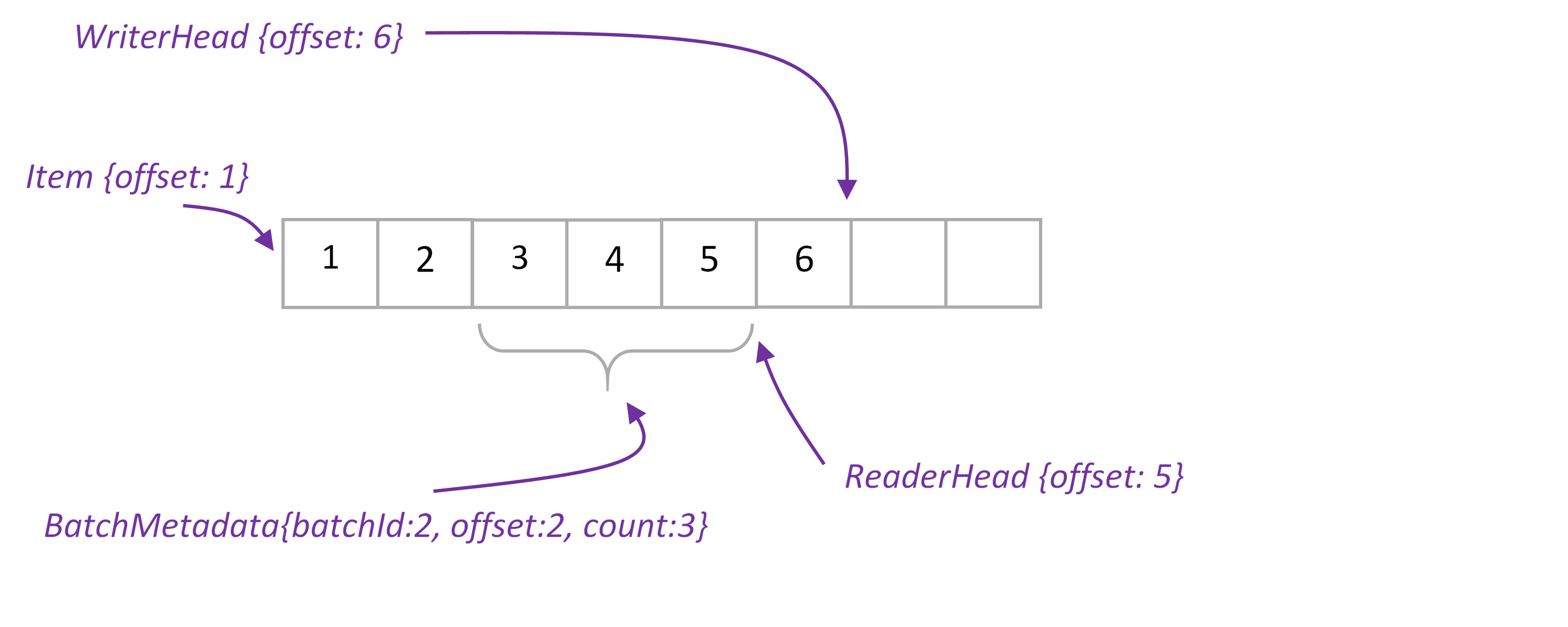
Stream’s WriterHead holds the last offset in the stream. Any time batch of elements (or single element) written to stream, WriterHead incremented by the number of elements. Allocated numbers used to populate offset property of Items. WriterHead object is kept in heap, there is no need to keep it in space. If primary partition fails, WriterHead is reinitialized to be the max offset value for given stream.
ReaderHead points to the last read item. We have to keep this value in the space, otherwise if partition fails we won’t be able to infer this value.
When spout request new batch, we take ReaderHead, read data from that point and update ReaderHead. New BatchMetadata object is placed to the space, it keeps start offset and number of items in the batch. In case Storm requests transaction replaying, we are able to reread exactly the same items by given batchId. Finally, once Storm acknowledges that batch successfully processed, we delete BatchMetadata and corresponding items from the space.
By default, Trident processes a single batch at a time, waiting for the batch to succeed or fail before trying another batch. We can get significantly higher throughput and lower latency of processing of each batch – by pipelining the batches. You configure the maximum amount of batches to be processed simultaneously with the “topology.max.spout.pending” property.
Operations with PartitionedStream are encapsulated in remote service – PartitionedStreamService.
Here is an example how to use XAPTransactionalTridentSpout:
1 2 3 4 5 6 7 8 9 | |
The full example that demonstrates usage of XAPTransactionalTridentSpout to address classic Word Counter problem can be found in XAPTransactionalTridentSpoutTest.
Trident State
Trident has first-class abstractions for reading from and writing to stateful sources. Details are available on the Storm wiki site.
In Trident topology that is persisting state via this mechanism, the overall throughput is almost certainly constrained by the performance of the state persistence. This is a good place where XAP can step in and provide extremely high performance persistence for stream processing state.
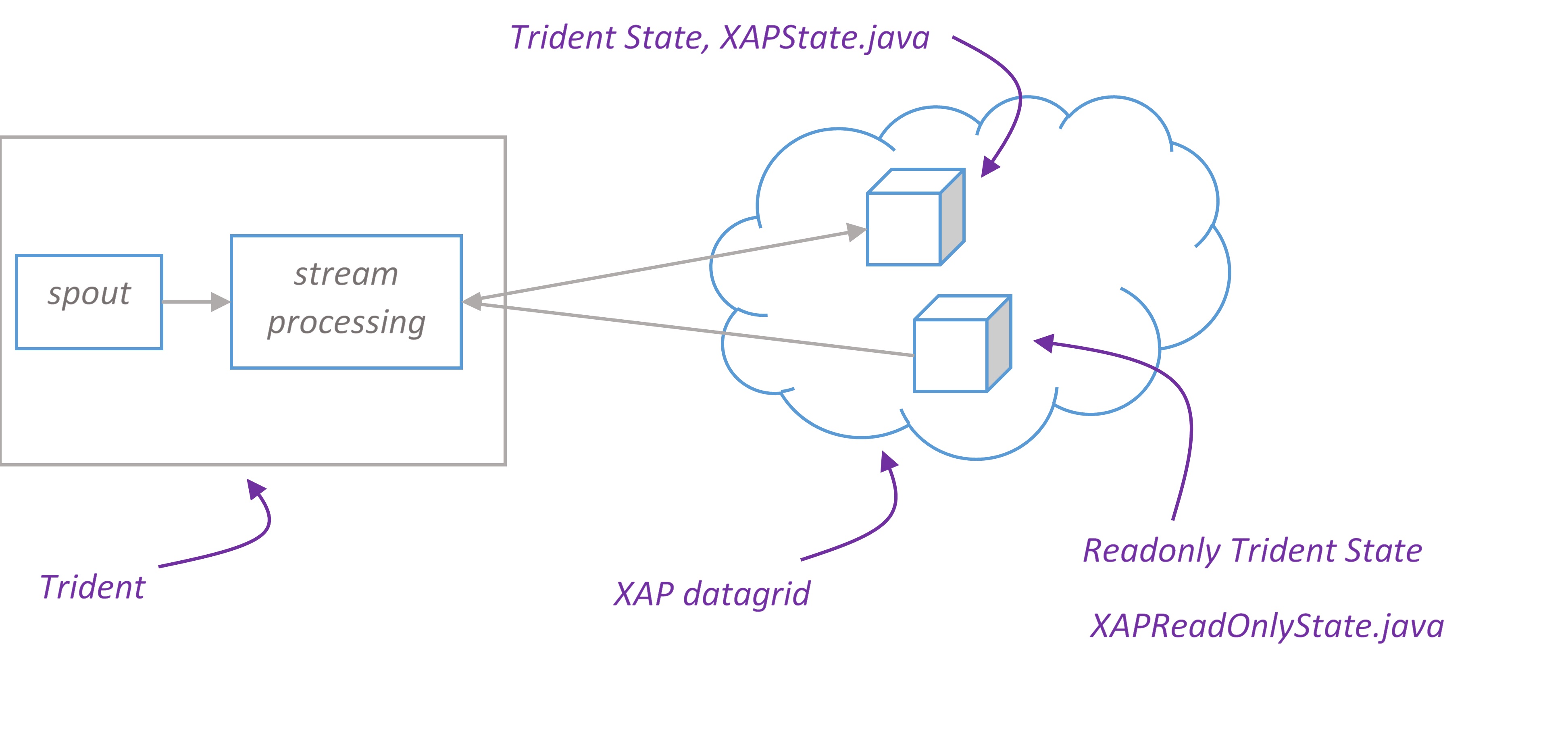
XAP Trident state implementation supports all state types – non-transactional, transactional and opaque. All you need to create a Trident state is configure space url and choose appropriate factory method of XAPStateFactory class:
1 2 3 4 5 6 7 8 9 | |
The full example can be found in TridentWordCountTest.
Trident Read-Only state
Trident Read-Only state allows to lookup persistent data during the computation.
Consider Twitter Reach example. Reach is the number of unique people exposed to a URL on Twitter. To compute reach, you need to fetch all the people who ever tweeted a URL, fetch all the followers of all those people, unique that set of followers, and that count that uniqued set.
XAP is a good candidate to store reference data such as tweeted url and followers. You can easily create XAP read-only state with XAPReadOnlyStateFactory. The following example demonstrates how to create a read-only state for TweeterUrl and Followers classes. The input arguments that Trident pass to stateQuery() are used as space ids.
The full example can be found in TridentReachTest.
1 2 3 4 5 6 7 8 9 10 11 | |
Another option to create XAP read-only state is to use SQL query. In this case stateQuery’s input arguments are used as SQL parameters:
1 2 | |
The full example can be found in SqlQueryReadOnlyStateTest.
Storm bolts
If pure Storm suits better your needs, most likely you will want to read/write data from bolts to persistent storage. For instance, imagine you are processing stream of data and would like to present computation result on UI. So the final bolt in your topology pipeline should write result to XAP which can then be accessed from anywhere. For this purpose we created XAPAwareRichBolt and XAPAwareBasicBolt that have a reference to space proxy. All you need is to configure space url and extend XAP aware bolt.
Example:
1 2 3 4 5 6 7 | |
Illustrative example: Real-time Google Analytics
In this section we demonstrate how to build highly available, scalable equivalent of Real-time Google Analytics application and deploy it to cloud with one click using Cloudify.
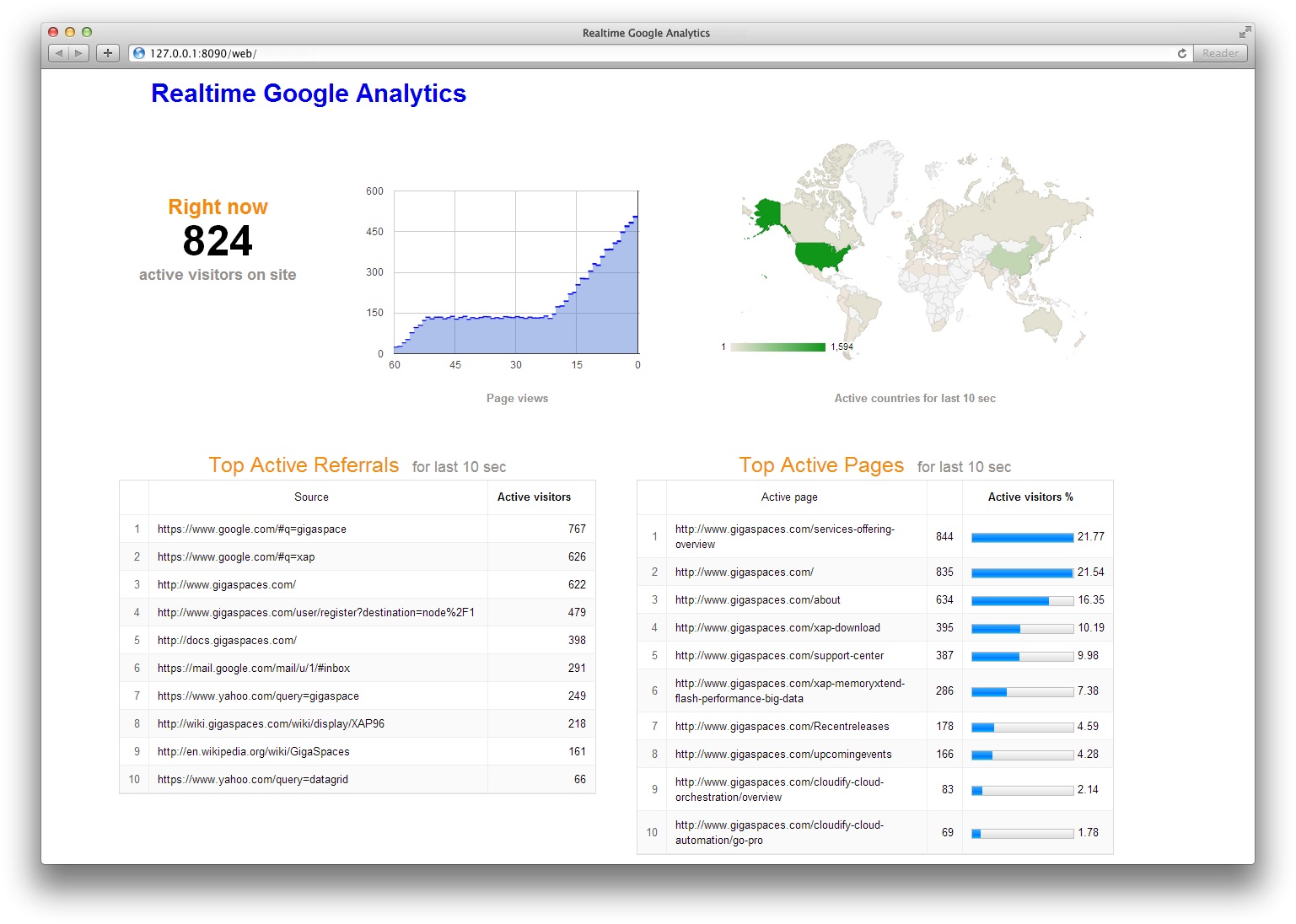
Real-Time Google Analytics allows you to monitor activity as it happens on your site. The reports are updated continuously and each page view is reported seconds after it occurs on your site. For example, you can see:
- how many people are on your site right now
- dynamic of page views during last minute
- users geographic locations
- traffic sources that referred them
- which pages or events they’re interacting with
High-level architecture diagram
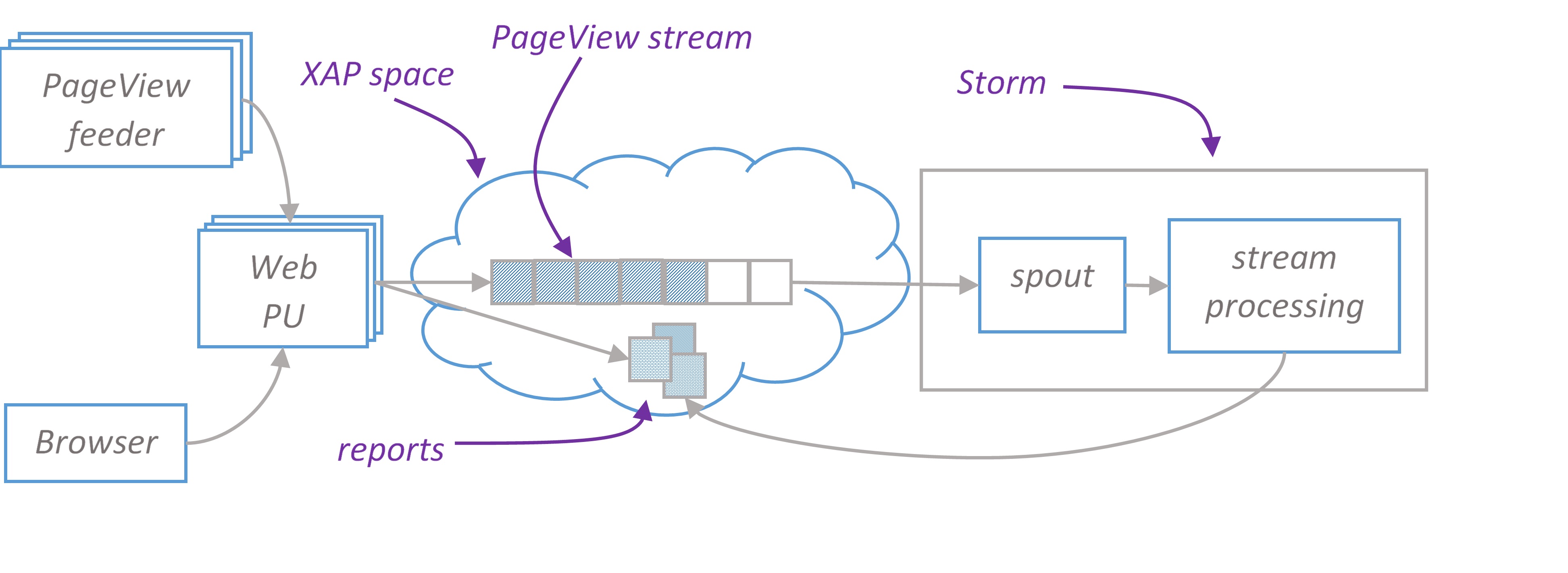
PageView feeder is a standalone java application that simulates users on the site. It continuously sends PageView json to rest service endpoints deployed in XAP web PU. PageView looks like this
1 2 3 4 5 6 | |
Rest service converts JSON documents to space object and writes them to the stream. Stream is consumed by Storm topology which performs all necessary processing in memory and stores results in XAP space. End user is browsing web page hosted in Web PU that continuously updates reports with AJAX requests backed by another rest service. Rest service reads report from XAP space.
We use pure Storm to build topology. There are several reasons why we don’t use Trident for this application. We are tolerant to page views loss if some Storm node fails. We don’t need exactly-once processing semantic. Instead, we want to maximize throughput and minimize latency.
Google Analytics Topology. High level overview.
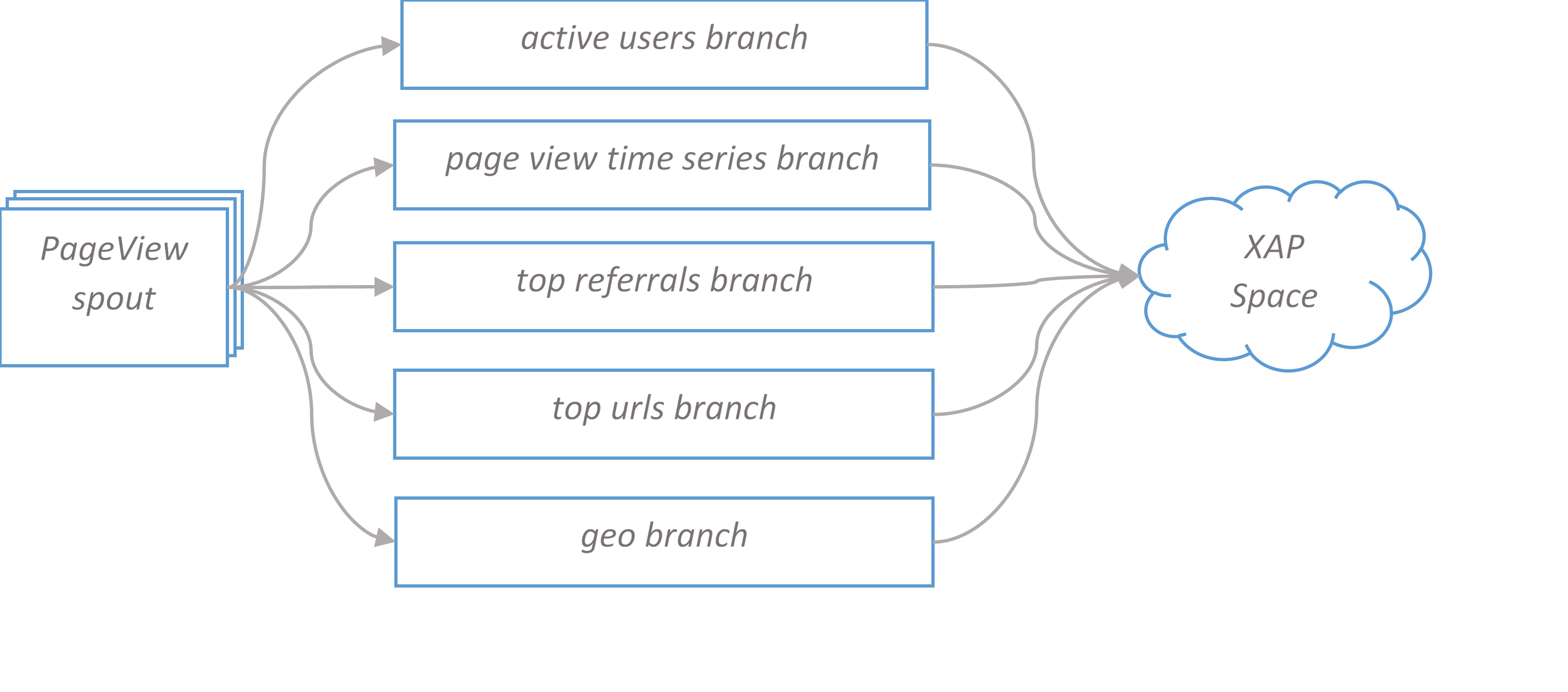
PageView spout forks five branches, each branch calculates its report and can be scaled independently. The final bolt in the branch writes data to XAP space. In the next sections we take a closer look at branches design.
Top urls topology branch
Top urls report displays top 10 visited urls for the last ten seconds. Topology implements distributed rolling count algorithm. The report is updated every second.
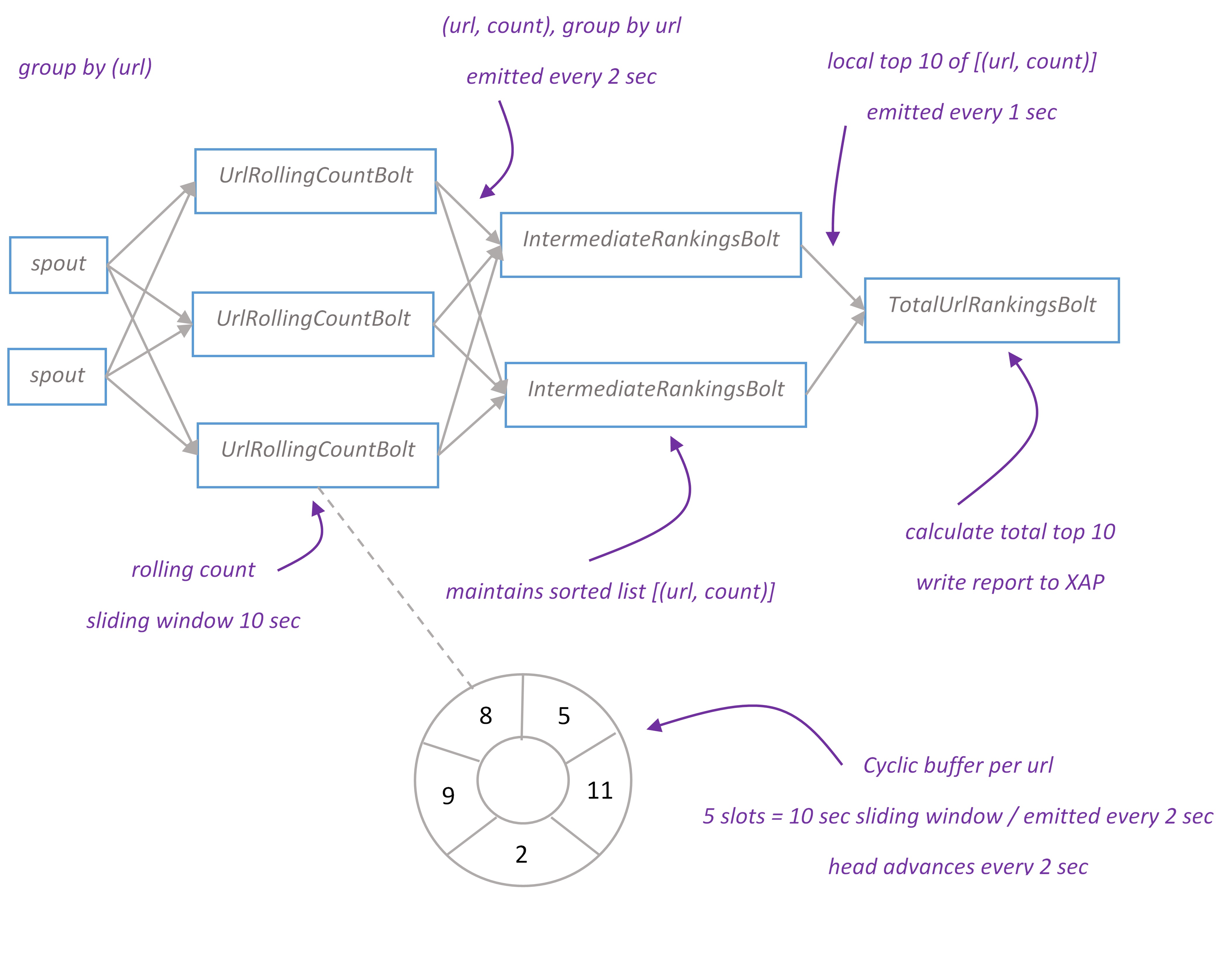
Tuples flow from spout to UrlRollingCountBolt grouped by ‘url’. UrlRollingCountBolt calculates rolling count with sliding windows of 10 seconds for every url. Sliding windows is basically a cyclic buffer with a head pointing to current slot. When bolt receives new tuple, it finds a sliding window for this tuple and increments the number in current slot. Every two seconds UrlRollingCountBolt emits the sum of sliding window for every url, then sliding windows advance and head points to the next slot.
The url and its rolling count flow to IntermediateRankingsBolt which maintains pair of (url, count) in sorted by count order and emits its top 10 urls to the final stage. TotalUrlRankingBolt calculates the global top 10 urls and writes report object to XAP space. The primitives to implement rolling count algorithm can be found in storm-starter project.
Top referrals topology branch is identical to top urls one. The only difference in is that we calculate ‘referral’ rather than ‘url’ tuple field.
Active users topology branch
Active users report displays how many people on the site right now. We assume that if user hasn’t opened any page for the last N seconds, then user has left the site. Users are uniquely identified by ‘sessionId’ tuple field. For demo purpose N is configured to 5 seconds, though it should be much longer in real life application.
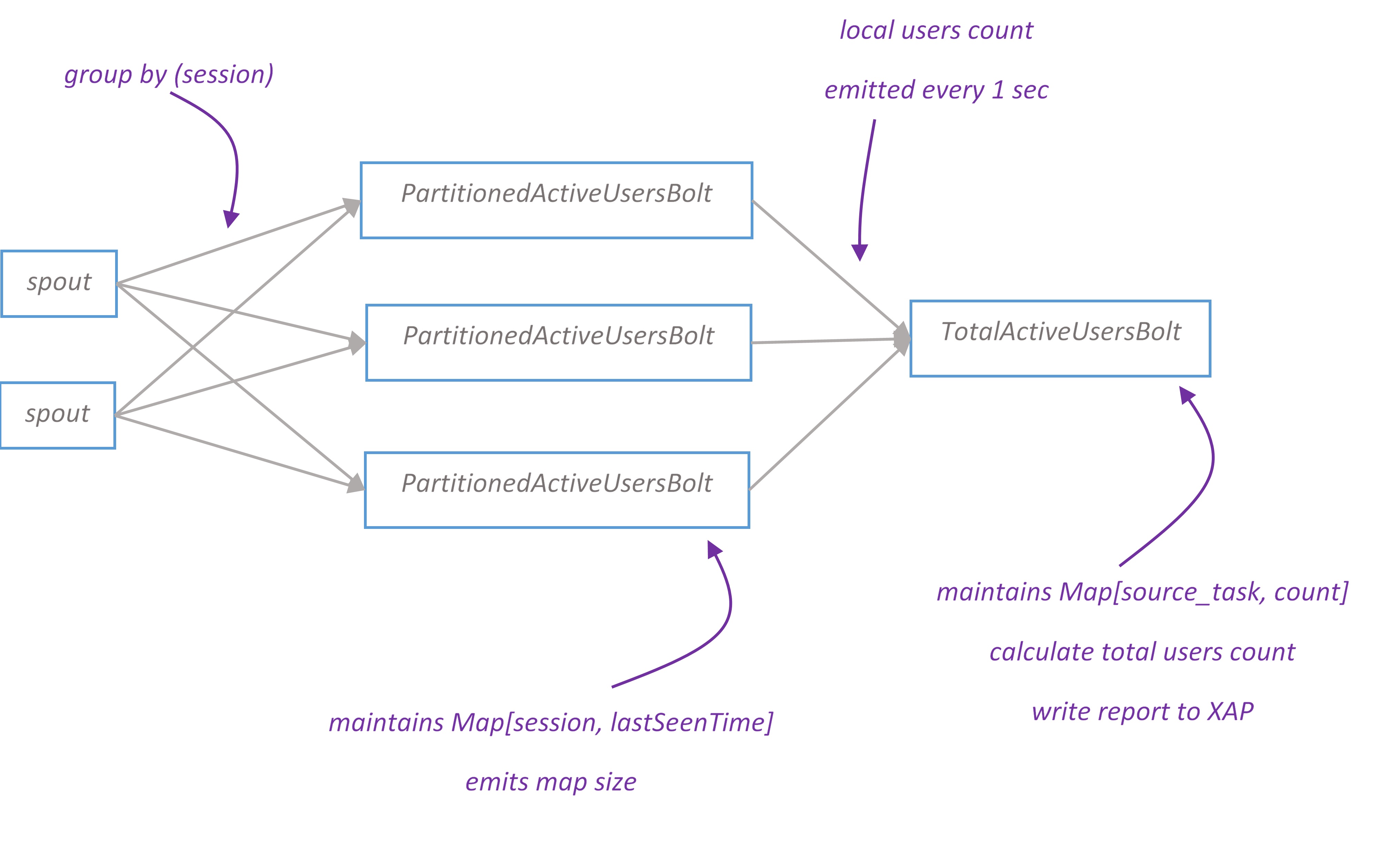
Tuples flow from spout to PartitionedActiveUsersBolt grouped by ‘sessionId’. For every sessionId PartitionedActiveUsersBolt keeps track of the last seen time. Every second it removes sessions seen last time earlier than N seconds before and then emits the number of remaining ones.
TotalActiveUsersBolt maintains a map of [source_task, count] and emits the total count for all sources. Report is written to XAP.
Page view time series topology branch
Page view time series report displays the dynamic of visited pages for last minute. The chart is updated every second.
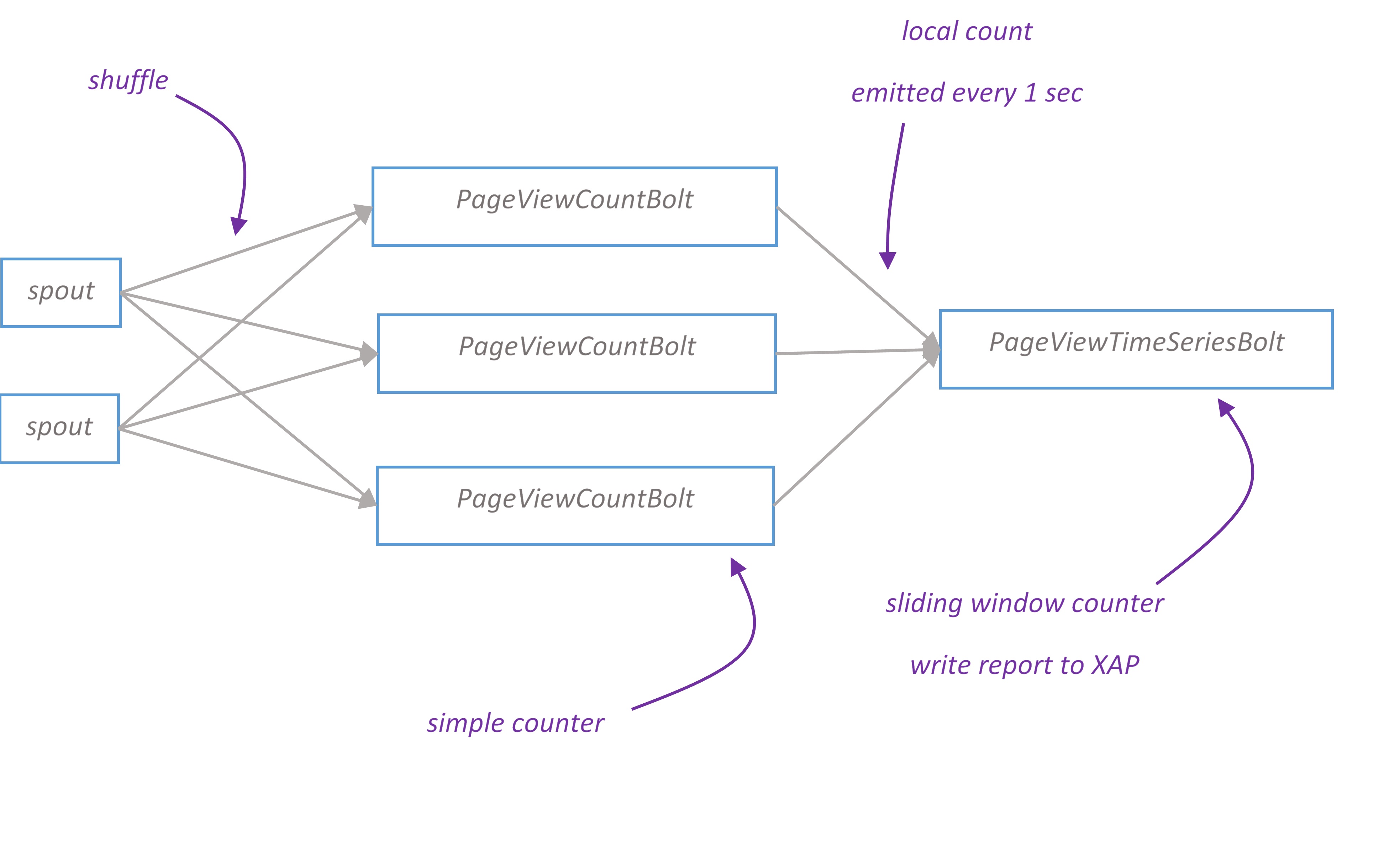
PageViewCountBolt calculates the number of page views and passes local count to PageViewTimeSeriesBolt every second. PageViewTimeSeriesBolt maintains a sliding window counter and writes report to XAP space.
Geo topology branch
Geo report displays a map of users’ geographical location. Depending on the volume of traffic from particular country, country is filled with different colors on the map.
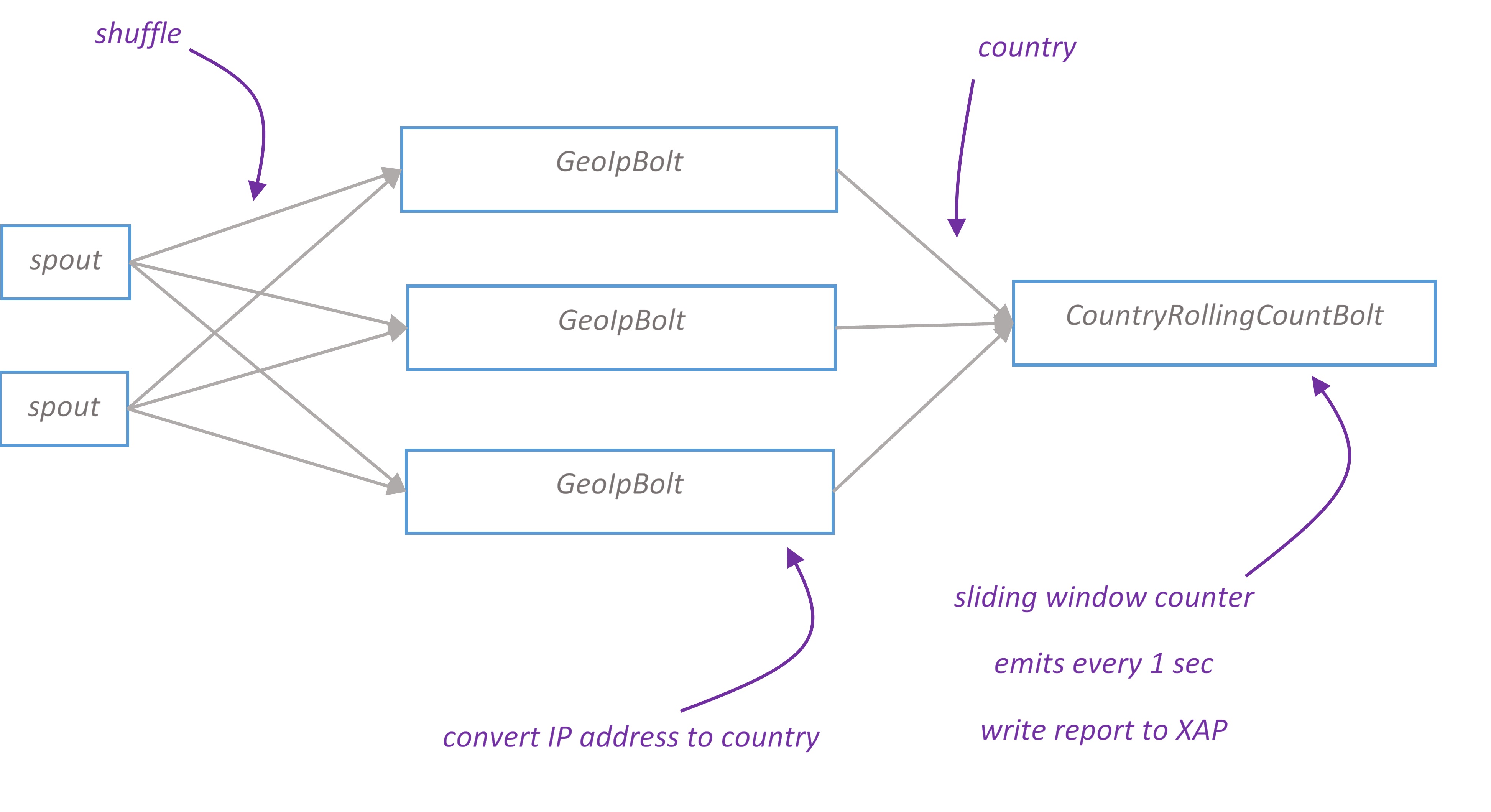
IP address converted to country using MaxMind GeoIP database. The database is a binary file loaded into GeoIPBolt’s heap. GeoIpLookupService ensures that it’s loaded only once per JVM.
Building the Application
- Download and install XAP
- Install Maven and the GigaSpaces Maven plug-in
- The application source can be found on github
- Build the project by running
mvn clean install
Deploying in development environment
- Follow this documentation to install and run Zookeeper, Nimbus, Supervisor and optionally Storm UI.
- Start a Grid Service Agent by running the
gs-agent.sh/batscript - Deploy space and Web PU by running the following from project root folder:
1 2 | |
- Add
apache-storm-0.9.2-incubating/binto your$PATH - Run the following to deploy topology to Storm cluster
storm jar ./storm-topology/target/storm-topology-1.0-SNAPSHOT.jar com.gigaspaces.storm.googleanalytics.topology.GoogleAnalyticsTopology google-analytics 127.0.0.1 - Run feeder
java -jar ./feeder/target/feeder-1.0-SNAPSHOT.jar 127.0.0.1 - Open browser http://localhost:8090/web/ to view Google Analytics UI
- To undeploy topology run
storm kill google-analytics
Deploying in development environment with embedded Storm
- To run topology in embedded Storm you don’t need to install Zookeeper and Storm. Follow all steps from previous section except deployment to Strom.
- Open
google-analytics/storm-topology/pom.xmland change scope of storm-core artifact from ‘provided’ to ‘compile’. - Rebuild the project
- Run storm topology
java -jar ./storm-topology/target/storm-topology-1.0-SNAPSHOT.jar. Alternatively you canGoogleAnalyticsTopologyfrom your IDE.
Deploying to cloud
Please note, recipes tested with Centos 6 only
- Install Cloudify 2.7
- Make sure that
<project_root>/cloudify/apps/storm-demo/deployer/filescontains up-to-date version ofspace-1.0.-SNAPSHOT.jar,web.warandfeeder-1.0-SNAPSHOT.jar. As well as<project_root>/cloudify/apps/storm-demo/storm-nimbus/commandscontainsstorm-topology-1.0-SNAPSHOT.jar(you can copy them from maven’s target directories using<project_root>/dev-scripts/copy-artifacts-to-cloudify.shscript) - Copy
<project_root>/cloudifyrecipes to<cloudify_install>/recipesdirectory - Run cloudify
<cloudify_install>/bin/cloudify.sh - Bootsrap cloud (to bootsrap local cloud, run the following in Cloudify Shell
bootstrap-localcloud) - Start installation
install-application storm-demo - Once installation completed, open Cloudify Management Console and check the ip address of
xap-managementservice. Google Analytics UI should be available athttp://<xap_management_service_ip>:8090/web