Spark Streaming is a popular engine for stream processing and its ability to compute data in memory makes it very attractive. However Spark Streaming is not self-sufficient, it relies on external data source and storage to output computation results. Therefore, in many cases the overall performance is limited by slow external components that are not able to keep up with Spark’s throughput and/or introduce unacceptable latency.
In this article we describe how we use GigaSpaces XAP in-memory datagrid to address this challenge. Code sources are available on github
Introduction
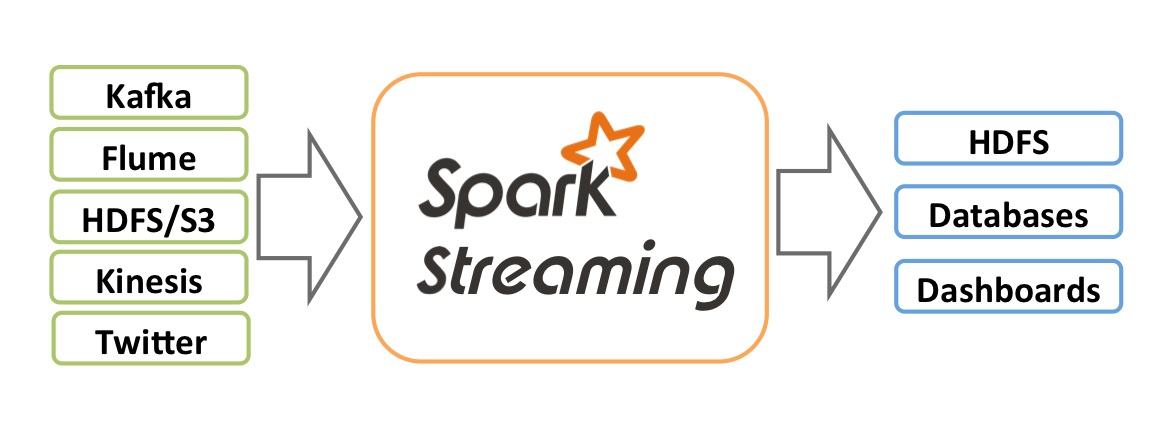
Real-time processing is becoming more and more popular. Spark Streaming is an extension of the core Spark API that allows scalable, high-throughput, fault-tolerant stream processing of live data streams.
Spark Streaming has many use cases: user activity analytics on web, recommendation systems, censor data analytics, fraud detection, sentiment analytics and more.
Data can be ingested to Spark cluster from many sources like HDS, Kafka, Flume, etc and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems or databases.
Challenge
Spark cluster keeps intermediate chunks of data (RDD) in memory and, if required, rarely touches HDFS to checkpoint stateful computation, therefore it is able to process huge volumes of data at in-memory speed. However, in many cases the overall performance is limited by slow input and output data sources that are not able to stream and store data with in-memory speed.
Solution
In this pattern we address performance challenge by integrating Spark Streaming with XAP. XAP is used as a stream data source and a scalable, fast, reliable persistent storage.
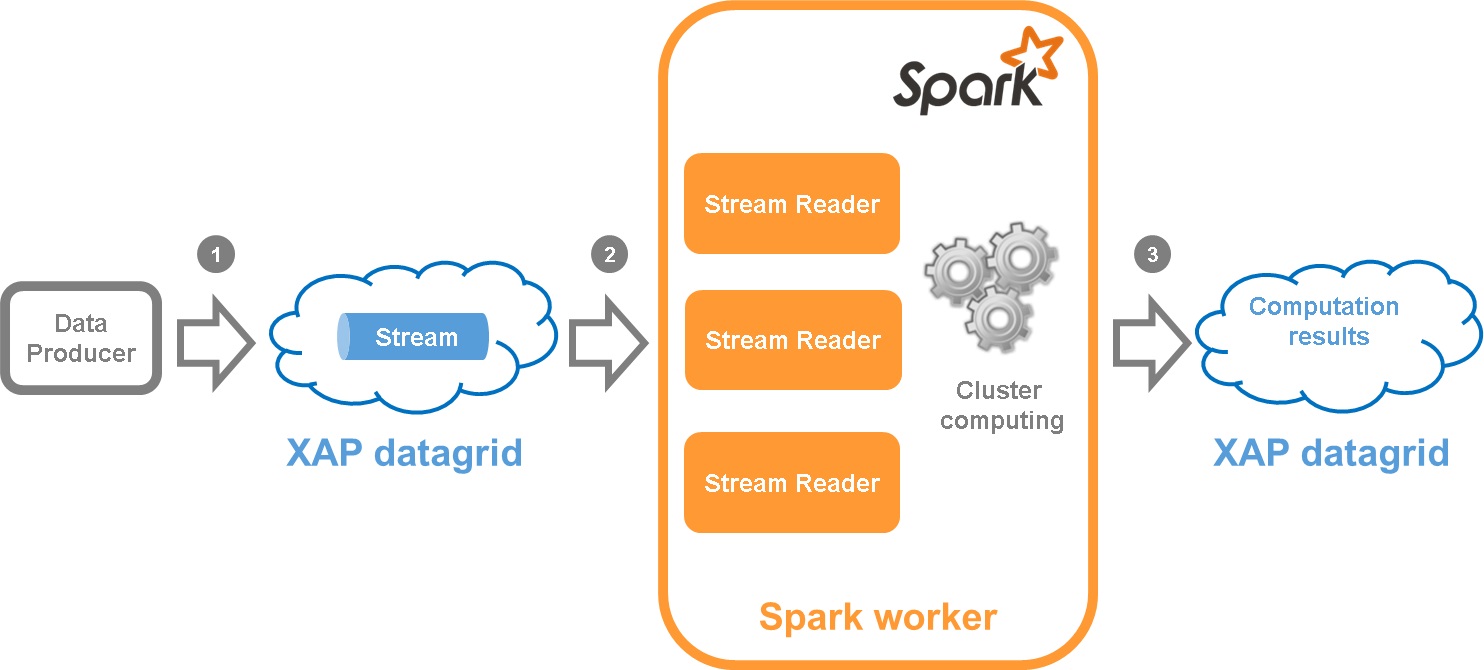
- Producer writes the data to XAP stream
- Spark worker reads the data from XAP stream and propagates it further for computation
- Spark saves computation results to XAP datagrid where they can be queried to display on UI
Let’s discuss this in more details.
XAP Stream
On XAP side we introduce the concept of stream. Please find XAPStream – an implementation that supports writing data in single and batch modes and reading in batch mode. XAPStream leverages XAP’s FIFO (First In, First Out) capabilities.
Here is an example how one can write data to XAPStream. Let’s consider we are building a Word Counter application and would like to write sentences of text to the stream.
At first we create a data model that represents a sentence. Note, that the space class should be annotated with FIFO support.
1 2 3 4 5 6 | |
Complete sources of Sentence.java can be found here
Spark Input DStream
In order to ingest data from XAP to Spark, we implemented a custom ReceiverInputDStream that starts the XAPReceiver on Spark worker nodes to receive the data.
XAPReceiver is a stream consumer that reads batches of data in multiple threads in parallel to achieve the maximum throughput.
XAPInputDStream can be created using the following function in XAPUtils object.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Here is an example of creating XAP Input stream. At first we set XAP space url in Spark config:
1 2 3 4 5 | |
And then we create a stream by merging two parallel sub-streams:
1 2 3 | |
Once the stream is created, we can apply any Spark functions like map, filter, reduce, transform, etc.
For instance, to compute a word counter of five-letter words over a sliding window, one can do the following:
1 2 3 4 5 6 | |
Output Spark computation results to XAP
Output operations allow the DStream’s data to be pushed out to external systems. Please refer to Spark documentation for the details.
To minimize the cost of creating XAP connection for each RDD, we created a connection pool named GigaSpaceFactory. Here is an example how to output RDD to XAP:
1 2 3 4 5 | |
Please, note that in this example a XAP connection is created and data is written from Spark driver. In some cases, one may want to write data from the Spark worker. Please, refer to Spark documentation - it explains different design patterns using
foreachRDD.
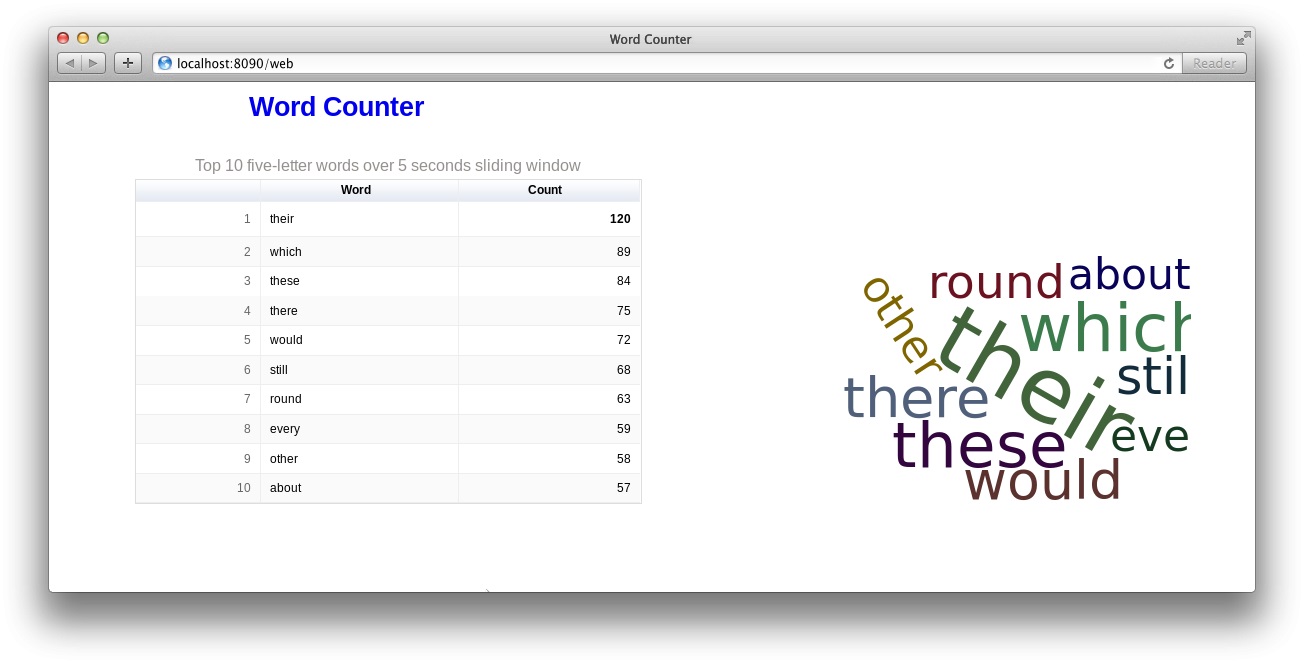
Word Counter Demo
As a part of this integration pattern, we demonstrate how to build an application that consumes live stream of text and displays top 10 five-letter words over a sliding window in real-time. The user interface consists of a simple single page web application displaying a table of top 10 words and a word cloud. The data on UI is updated every second.
High-level design
The high-level design diagram of the Word Counter Demo is below:
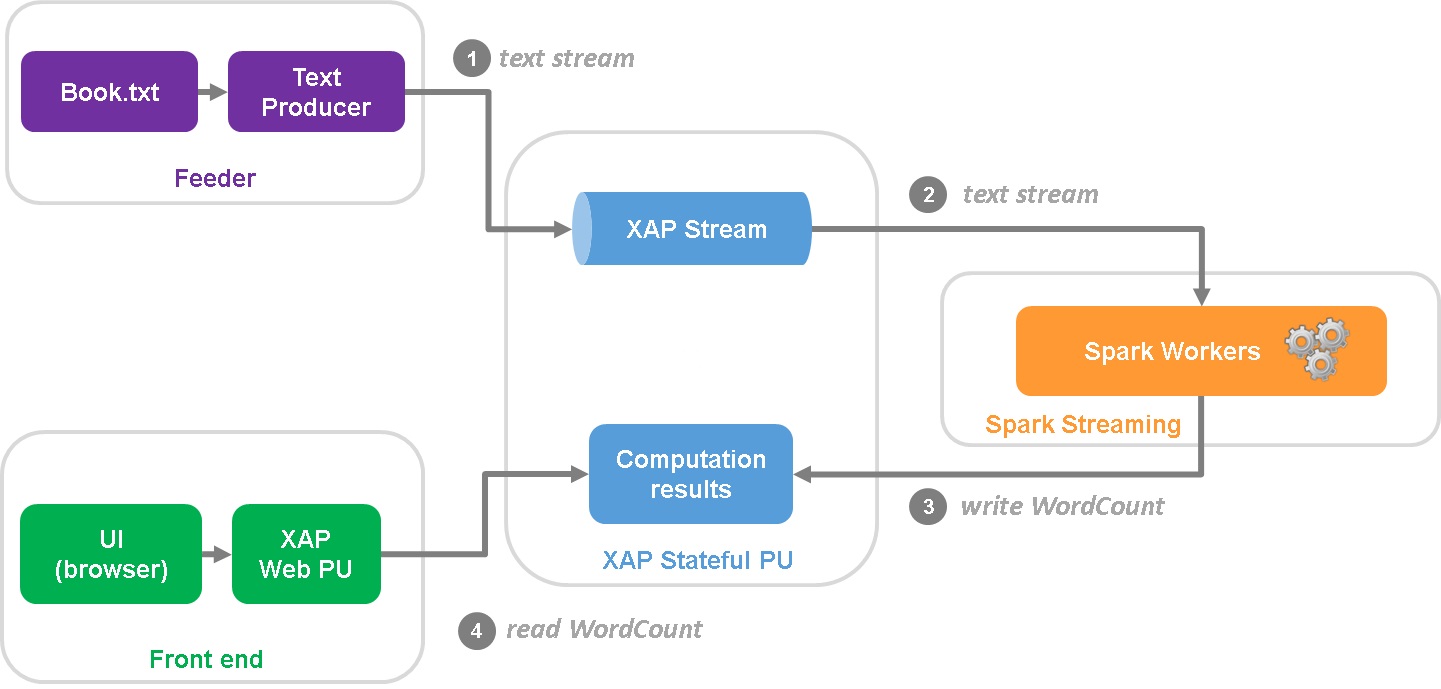
- Feeder is a standalone scala application that reads book from text file in a cycle and writes lines to XAP Stream.
- Stream is consumed by the Spark cluster which performs all necessary computing.
- Computation results are stored in the XAP space.
- End user is browsing the web page hosted in a Web PU that continuously updates dashboard with AJAX requests backed by the rest service.
Installing and building the Demo application
- Download XAP
- Install XAP
- Install Maven and the XAP Maven plug-in
- Download the application source code
- Build a project by running
mvn clean install
Deploying XAP Space and Web PU
- Set the XAP lookup group to
sparkby addingexport LOOKUPGROUPS=sparkline to<XAP_HOME>/bin/setenv.sh/bat - Start a Grid Service Agent by running the
gs-agent.sh/batscript - Deploy a space by running
mvn os:deploy -Dgroups=sparkfrom<project_root>/word-counter-demodirectory
Launch Spark Application
Option A. Run embedded Spark cluster
This is the simplest option that doesn’t require downloading and installing Spark distributive, which is useful for the development purposes. Spark runs in the embedded mode with as many worker threads as logical cores on your machine.
- Navigate to the
<project_root>/word-counter-demo/spark/targetdirectory - Run the following command
java -jar spark-wordcounter.jar -s jini://*/*/space?groups=spark -m local[*]
Option B. Run Spark standalone mode cluster
In this option Spark runs a cluster in the standalone mode (as an alternative to running on a Mesos or YARN cluster managers).
Run Spark
- Download Spark (tested with Spark 1.2.1 pre-built with Hadoop 2.4)
- Follow instructions to run a master and 2 workers. Here is an example of commands with hostname
fe2s(remember to substitute it with yours)
1 2 3 | |
Submit application
- Submit an application to Spark (in this example driver runs locally)
- Navigate to the
<project_root>/word-counter-demo/spark/targetdirectory - Run
java -jar spark-wordcounter.jar -s jini://*/*/space?groups=spark -m spark://fe2s:7077 -j ./spark-wordcounter.jar - Spark web console should be available at http://fe2s:8080
Launch Feeder application
- Navigate to
<project_root>/word-counter-demo/feeder/target - Run
java -jar feeder.jar -g spark -n 500
At this point all components should be up and running. The application is available at http://localhost:8090/web/