Recently I was involved into discussion of SaaS application design. One of the questions was how to manage configuration in large scale SaaS. The rise of clouds, microservices and container virtualization influence approaches used in configuration management. In this article we will look what we can learn from these concepts and how we can apply these lessons in SaaS and other generic distributed systems. In the second part of the article, we will build a PoC of elastic tenant aware application leveraging Zookeeper with 200 lines in Scala.
Before considering any architecture, let’s refresh what requirements are essential for typical SaaS application:
- elasticity, ability to add and remove tenants in runtime with zero system downtime
- scalability, ability to handle growing amount of users
- availability, the service should stay functional and usable to fulfil business requirements
(we skip other fundamental requirements such as security as they are not primary focus of the article)
Okay, how do we usually deal with scalability concerns?
When it comes to application services(or application servers), we prefer making them stateless, so we can simply run multiple copies and distribute load between them achieving scaling out (horizontal) capabilities. And what about availability? Pretty the same, run redundant copies of your service. So far so good.
Okay, but having hundreds of customers(tenants) multiplied on number of application servers per customer requires unreasonable overhead on memory, CPU and other hardware resources. Usually customers are different in size, usage patterns and timezones. Under these conditions generated load is spread unequally and lead to suboptimal resources utilization. Further cost overhead comes from licenses of underlying software(databases, application servers, operating systems, etc).
Multitenancy comes to the rescue. Multitenancy implies the ability to serve multiple tenants with a single application instance thus spreading the load more equally and amortizing infrastructure overhead. Though multitenancy is not free, the downside is the increased engineering complexity that requires additional development effort. On the other hand some of these issues can be partially addressed with virtualization, it looks attractive since doesn’t require any significant architecture redesign.
Having scalable application server layer is only part of the problem, with growing amount of customers the data storage has to be scalable as well. Designing multitenant data storage is another huge topic, we will not dig into consideration details. While NoSQL solutions are able to scale out of the box, with relational databases we have to scale them manually allocating database instance per one or several customers, thus application server instance may talk to multiple databases.
Remember, in dynamic scalable SaaS environment application servers, databases and load balancer instances come and go while relying on each other combining a distributed cluster. The load balancer should know about application server instances, and application server instance should talk to databases. So when the database for new customer is provisioned, some or all application servers have to be notified about database layer changes and load balancer has to be notified of all changes in a farm of application servers. In short, we need an ability to link the pieces of multi-tier application together in realtime.
Configuration management tools like Chef, Puppet, etc are able to configure a node based on centralized configuration, though they are not designed to be responsive and propagate configuration changes quickly. Additionally they are not designed to detect failures or tolerate network partitions.
If you think about multi-tier configuration in a more abstract way, you will easily recognize service registry and service discovery patterns that people use many years building distributed systems.
Even more, with the rise of container based virtualization and Docker in particularly, service discovery becomes very important part. Containers need an ability to discovery each other adopting to the current environment.
Let’s see how SaaS configuration will look from service discovery perspective.
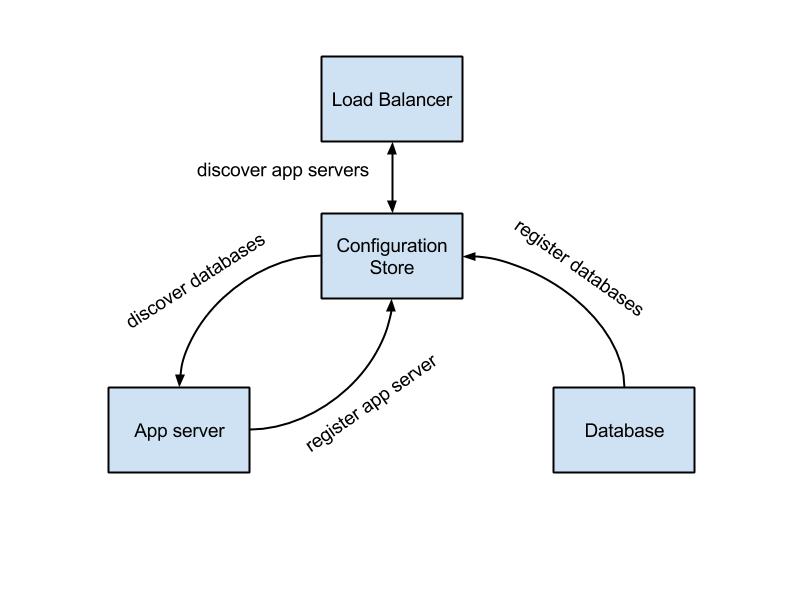
Okay, but can we just use simple database with inserts and selects to register and discovery? Well, there are a few concerns with that:
- availability, configuration store should be distributed and tolerate nodes failure, otherwise it will be a single point of failure.
- service failure detection, we need some sort of services monitoring, if service goes down, dependent services should react correspondingly. The are several approaches for failure detection design. Client can keep TCP connection indicating it’s alive, service can periodically send messages or configuration store itself can monitor service endpoint. This design decision is a subject for debates, one should consider what is reasonable in the context. There a few available service discovery tools following these patterns.
Now that we have discussed the high level design and requirements of configuration store, we can briefly mention open source tools: Zookeeper, Consul, etcd, Eureka, SmartStack, Doozer, Serf, etc.
I would highlight three of them definitely worth checking:
- Apache Zookeeper. Written in Java, choses consistency over availability, old, mature, battle-tested, very popular in middleware(Hadoop, Kafka, Storm, etc). Hard to use properly because of low level API. Consider using existing recipes or Curator library.
- HashiCorp Consul. Written in Go, flexible between consistency and availability, new and promising, high level features out of the box, multi datacenter support.
- Airbnb SmartStack. Written in Ruby on top of Zookeeper and HAProxy, unique design where application service talks to HAProxy on localhost, adds Zookeeper caching to favour availability over consistency.
Part 2. Building a PoC
Let’s build a simple demo application to proof the concept described above. We will try to simplify things as much as possible sacrificing correctness and errors handling sometimes, but still suitable for illustration purpose. Note, one should leverage existing Curator service discovery recipes when building production quality applications. The source code is available on github
For this PoC we choose tenant aware model rather than multitenancy to demonstrate how to incorporate custom logic with service discovery. In this model client (tenant) is routed to a configurable number of application services while they use common database.
Beware that this model has its drawbacks such as weaker scale-in (reducing the quantity of servers) and cost saving capabilities since the load is not equally spread comparing to true multitenancy. On the other hand this can be compensated with container virtualization in some sort. Also this model implies support of multiple release versions of application and has better support of application level caching. Again, the tenancy model itself is not a subject here rather than a centralized configuration.
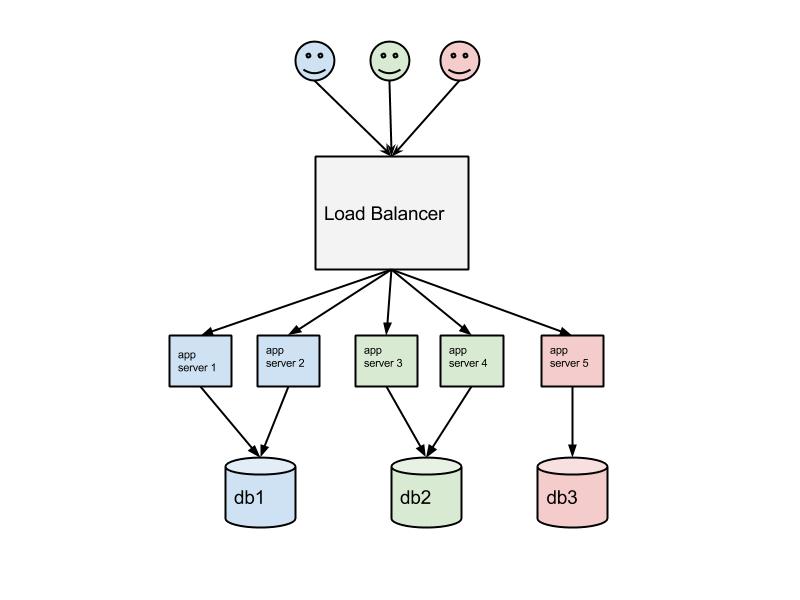
Our stack is:
- Scala
- Zookeeper for configuration store
- Curator library as a client for Zookeeper
- Spray(runs on top of Akka) for lightweight http services
- HAProxy load balancer
Zookeeper data model
We define Zookeeper data model as a following hierarchical structure.
/app
/client-{id}
/db
/app-server-slots
Znode /db contains database details such as connection url. Znode /app-server-slots defines the maximum number of application server instances we want to run for given client.
Here is an example with 3 clients, the value of znode follows = sign.
/app
/client-1
/db = jdbc://db-client-1:5555
/app-server-slots = 2
/client-2
/db = jdbc://db-client-2:5555
/app-server-slots = 2
/client-3
/db = jdbc://db-client-3:5555
/app-server-slots = 1
Service registration is implemented using so called ephemeral znodes. Unlike standard znodes they exist as long as the session that created the znode is active.
When application server starts it registers itself creating ephemeral znode under corresponding client. Respectively when application server is brought down or it failures for some reason, the ephemeral znode is automatically deleted. The value of znode contains http service location.
/app
/client-1
/db = jdbc://db-client-1:5555
/app-server-slots = 2
/app-server#0000000001 = host1:56003
Load Balancer configuration
We use HAProxy as a load balancer. To reconfigure HAProxy in runtime we created a simple agent that runs alongside HAProxy process and watches for any configuration changes. Once it detects any changes in Zookeeper, it rewrites HAProxy config and send a command to reload it.
How it works in action
At first we start Zookeeper zkServer.sh start
Then we create some data model to play with by running ZkSchemaBuilder.scala. You can browse zookeeper data with zkCli.sh tool.
Start HAProxy /haproxy/start.sh and HAProxy agent running HAProxyAgent.scala
Starting HAProxy agent Thread[main,5,main]
/client-1
/client-2
/client-3
Rewriting HAProxy config /Users/fe2s/Projects/zk-tenant/haproxy/haproxy.conf
Reloading HAProxy config
At this point we should be able to hit http://localhost:8080/ though it will return 503 since there are no actual backend services running. Let’s fix it.
Run Boot.scala to start application server with http service.
[INFO] [06/01/2015 20:22:16.084] [on-spray-can-akka.actor.default-dispatcher-2] [akka://on-spray-can/user/IO-HTTP/listener-0] Bound to Oleksiis-Mac-mini.local/192.168.0.100:57581
registering service available at Oleksiis-Mac-mini.local:57581
looking for a client with free slots
client client-1 slots: 2 occupied: 0
Found client client-1 with available slot(s) ... registering
Configuring HttpService with dbUrl jdbc://db-client-1:5555
We see that http service was brought up for client-1 that had 2 available slots.
Now run Boot.scala several more times to start more servers and check haproxy/haproxy.conf
defaults
mode http
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
frontend http-in
bind *:8080
acl client-1-path path_beg /client-1
acl client-2-path path_beg /client-2
acl client-3-path path_beg /client-3
use_backend client-1-backend if client-1-path
use_backend client-2-backend if client-2-path
use_backend client-3-backend if client-3-path
backend client-1-backend
balance roundrobin
server app Oleksiis-Mac-mini.local:57581
server app Oleksiis-Mac-mini.local:57588
backend client-2-backend
balance roundrobin
server app Oleksiis-Mac-mini.local:57591
server app Oleksiis-Mac-mini.local:57595
backend client-3-backend
balance roundrobin
server app Oleksiis-Mac-mini.local:57598
As we see HAProxy agent observed and propagated all configuration changes to haproxy.conf. We use HAProxy acl feature to route http requests by url prefix, i.e. requests starting with /client-1 will be routed to a farm of application servers serving for client-1.
Now if we hit http://localhost:8080/client-1/test we should get a response “OK. Http service configured with db url: jdbc://db-client-1:5555”. Voila!
You should also notice that killing an application server process will result in immediate reconfiguration of HAProxy.